Programy służące do optycznego rozpoznawania tekstu (z angielskiego OCR - Optical Character Recognition), są bardzo ciekawymi i użytecznymi programami. Służą do rozpoznawania pisma (nawet odręcznego) oraz jego cech formatowania. Często ich mechanizmy są stosowane w analizowaniu tysięcy ankiet, a ich zasada działania tych programów opiera się na rozpoznawaniu wzorców.
Mają niewątpliwie szereg zastosowań, począwszy od zastąpienia pracy człowieka przy przepisywaniu dużej ilości papierków, przez przenoszenie zbiorów bibliotek do zasobów cyfrowych, a skończywszy na pomocy niepełnosprawnym.
Aplikacją tego typu, którą najbardziej znanamy jest niewątpliwie FineReader firmy ABBYY. Oczywiście są inne tego typu aplikacje, o których się mniej słyszy. Jak aplikacje tego typu poradzą sobie w teście? Czy ABBYY FineReader jest rzeczywiście najlepszym tego typu programem, czy może lepszym rozwiązaniem jest któraś spośród innych aplikacji? Na te oraz inne pytania postaram odpowiedzieć się w teście. Zapraszam!
Przedstawienie konkurentów
ABBYY FineReader 10


- cena: 479zł
- autor: ABBYY
- najnowsza wersja: 10.0.102.82
- język interfejsu: polski
- obsługiwane języki: angielski, armeński, baszkirski, bułgarski, chorwacki, czeski, duński, estoński, fiński, francuski, grecki, hebrajski, hiszpański, holenderski, indonezyjski, kataloński, litewski, łotewski, niemiecki, norweski, polski, portugalski, rosyjski, rumuński, słowacki, słoweński, szwedzki, tajlandzki, tatarski, turecki, ukraiński, węgierski, włoski, chiński, japoński, koreański
+ bardzo dużo innych specjalnych na przykład eskimoski, esperanto czy PASCAL
Cueiform (Open OCR)
- cena: darmowy
- autor: Cognitive Technologies Ltd.
- najnowsza wersja: 1.0.0.1
- język interfejsu: angielski
- obsługiwane języki: angielski, bułgarski, chorwacki, czeski, duński, estoński, francuski, hiszpański, litewski, łotewski, niemiecki, polski, portugalski, rosyjski, rumuński, serbski, słoweński, szwedzki, turecki, ukraiński, węgierski, włoski
Puma.NET

- cena: darmowy
- autor: Maxim Saplin
- najnowsza wersja: 1.0.0.0
- język interfejsu: angielski
- obsługiwane języki: angielski, bułgarski, chorwacki, czeski, estoński, duński, francuski, hiszpański, litewski, niemiecki, polski, portugalski, rumuński, rosyjski, serbski, słoweński, szwedzki, ukraiński, węgierski, włoski,
SimpleOCR/SoftWriting

- cena: darmowy
- autor: Meta Enterprises, LLC
- najnowsza wersja: 3.1
- język interfejsu: angielski
- obsługiwane języki: angielski, francuski, holenderski
Interfejs
ABBYY FineReader 10
Interfejs FineReader'a jest bardzo intuicyjny. Dokument do rozpoznania możemy dostarczyć w formie pliku graficznego (BMP, JPG, PNG, TIFF), PDF'a lub po prostu zeskanować interesujący nas fragment. Bardzo przydatną funkcją jest możliwość dodania paru języków rozpoznawanego tekstu. Po zanalizowaniu dostarczonego materiału, ekran jest podzielony na dwie części – jedna z nich to oryginalny dokument, a druga to dokument po rozpoznaniu tekstu. Oczywiście rozpoznany już fragment możemy sami skorygować, a pomaga nam w tym zaznaczony na niebiesko, niepewny według programu, fragment tekstu. Rozpoznany fragment możemy zapisać w formatach: DOC, XLS, PPT, PDF, HTML, RTF, CSV, czy po prostu jako plik tekstowy. Bardzo ciekawą opcją jest możliwość odzyskania dokumentu, podczas gdy na przykład program się zawiesił. Dostępnych opcji konfiguracji jest dużo.
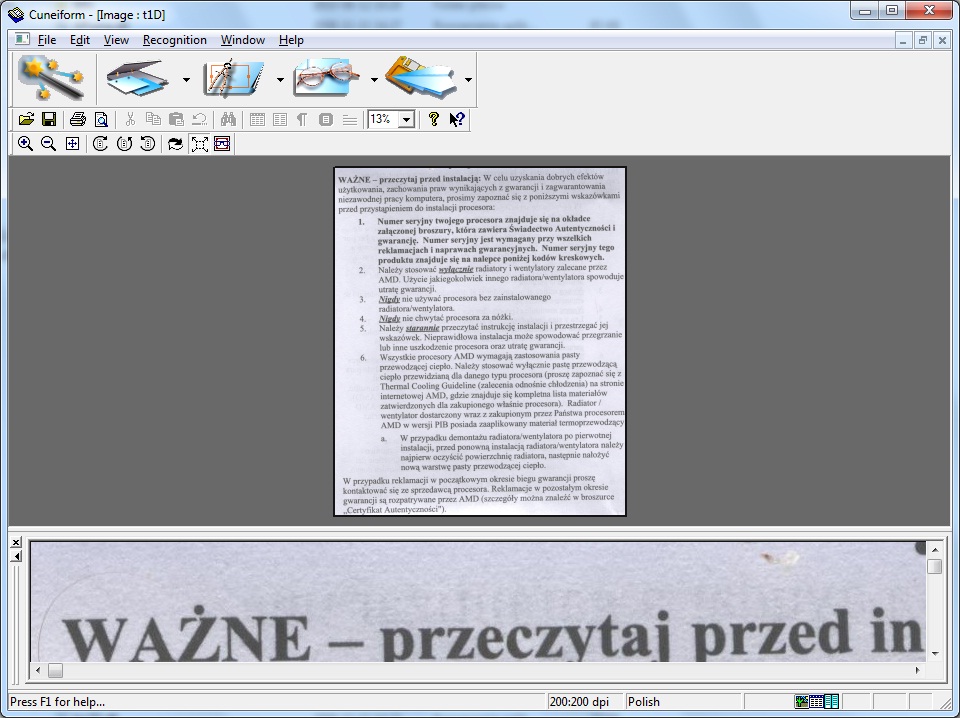
Cueiform (Open OCR)
Interfejs Cueiform'a jest trochę ubogi. Obraz do rozpoznania dostarczamy w pliku graficznym lub poprzez zeskanowanie go skanerem. Podgląd rozpoznanego materiału dostępny jest w edytorze Word, a gdy go nie mamy możemy go zapisać w formacie RTF. Dostępnych opcji konfiguracji jest niewiele.
Puma.NET
Interfejs jest bardzo ubogi. Plik do analizy możemy dostarczyć tylko w formie pliku graficznego (BMP, JPG, TIFF, GIF, PNG). Rozpoznany materiał możemy eksportować do formatu: RTF, DOC lub TXT. Dostępnych opcji konfiguracji jest mało, ale co ciekawe możemy włączyć takie rzeczy jak rozpoznawanie obrazków czy tabel.
SimpleOCR/SoftWriting
Interfejs programu jest bardzo ubogi. Zaraz po rozpoczęciu pracy mamy do wyboru rozpoznawanie pisma maszynowego/komputerowego (SimpleOCR) lub odręcznego (SoftWriting). W trybie rozpoznawania odręcznego pisma, musimy sami nauczyć program naszego pisma. Dokument do analizy możemy dostarczyć poprzez zeskanowanie go albo wskazanie pliku graficznego. Warto wspomnieć o tym, że materiał jest od razu konwertowany do postaci monochromatycznej, która często przypominała złej jakości ksero. Taka operacja na pewno odbija się na jakości rozpoznania tekstu. Rozpoznany materiał ukazuje się w postaci tekstowej, gdzie są wyszczególnione niepewne wyrazy, które potem możemy poprawić. Poprawiony tekst możemy zapisać do formatu DOC lub w pliku tekstowym. Opcji konfiguracji jest mało.
Testy
Platforma testowa:
- Procesor: AMD Athlon II X2 240 @ 3,5GHz
- Płyta główna: ASRock A785GXH/128M
- Karta graficzna: AMD/Ati Radeon HD 4200 128MB + 512MB; 850/400MHz
- Pamięci RAM:
G.SKILL 2x1GB 1000MHz CL5 @ 1000MHz CL6
GOODRAM 1GB 800MHz CL5 @ 1000MHz CL6 - Dysk twardy: WD WD3200AAKS
- Zasilacz: OCZ MODXSTREAM PRO 500W
- System operacyjny: Windows 7 32bit
- Skaner: HP ScanJet 3400C
System Windows 7 nie ma sterowników do skanera wymienionego wyżej, a na witrynie producenta próżno szukać ich do systemów nowszych niż Windows XP, więc materiały były skanowane bezpośrednio w trybie XP (coś na kształt maszyny wirtualnej dla systemu Windows7, dostarczonej przez Microsoft aby rozwiązywała problemy z niekompatybilnością programów i urządzeń).
Z racji tego, że nie wszystkie programy obsługują skanowania wprost z aplikacji, materiały do rozpoznania były najpierw zeskanowane skanerem (w rozdzielczości maksymalnej - 600DPI), a potem podane do rozpoznania poszczególnym aplikacją w formacie JPG.
We wszystkich programach wyniki rozpoznania tekstu nie były korygowane, pomimo tego, że program oferował taką funkcję – uznawałem to co program pokazał zaraz po rozpoznaniu. Jedyne co zostawało ustawiane to język jaki program ma rozpoznawać (oczywiście jeżeli było to możliwe).
Jako, że w programie ABBYY FineReader dostępny jest podgląd rozpoznania, to właśnie ten podgląd jest prezentowany na zrzucie ekranu. Natomiast w programach Cueiform, Puma.NET oraz SimpleOCR/SoftWriting wyniki zostawały bezpośrednio przenoszone do pliku RTF lub DOC, a następnie otwierane programem OpenOffice. Zrzut ekranu prezentuje rozpoznany tekst po przeniesieniu do programu OpenOffice.
Interesowały mnie także czasy rozpoznawania poszczególnych próbek przez aplikacje, więc i to się liczyła. Oczywiście miało to nieporównywalnie, mały wymiar w porównaniu do poprawność rozpoznanego tekstu.
Testy zwykłe
Test 1
Pierwszy test polegał na rozpoznaniu pisma drukowanego w języku polskim.
Tekst pochodzi z instrukcji dołączonej do procesora AMD. Można powiedzieć pierwszy test na rozgrzewkę...

oryginalny obraz
ABBYY FineReader

Cueiform (Open OCR)

Puma.NET

SimpleOCR


Nie da się ukryć, że w tym teście najdokładniej rozpoznał tekst ABBYY FineReader, ale potrzebował znacznie więcej czasu w porównaniu do innych programów. Tekst jest rozpoznany bezbłędnie. Oczywiście program miał parę wątpliwości (zaznaczone na niebiesko), ale okazały się niezasadne. Układ tekstu został zachowany.
Ciut gorzej poradziły sobie programy Cueiform oraz Puma.NET. Oba programy rozpoznały tekst prawie tak samo (są obecne drobne różnice). Jest to spowodowane najprawdopodobniej tym samym silnikiem lub metodą rozpoznawania tekstu. Błędów jest tylko trochę – po dodatkowej obróbce tekst byłby tak doskonały jak w ABBYY Finereader. Układ tekstu jest odpowiedni.
Najgorzej poradził sobie SimpleOCR. Tekst ma dużo błędów w postaci na siłę „wciskanych” słów angielskich, gdyż program nie posiada możliwości rozpoznawania języka polskiego. Dodatkowo układ tekstu jest nieodpowiedni.
Bardzo szybko (a do tego nawet sprawnie) poradziły sobie z testem programy Cueiform oraz Puma.NET. ABBYY Finereader wymagał do sprawdzenia najwięcej czasu.
Test 2
Drugi test był ciut bardziej wymagający - polegał na rozpoznaniu fragmentu dzieła Adama Mickiewicza pod tytułem „Dziady część III”, w formie drukowanej. Warto dodać, że tekst był oczywiście w języku polskim, ale w jego starszej odmianie - część wyrazów wyszła już z użycia. Dodatkowymi utrudnieniami była prześwitująca następna strona oraz lekko pochylony tekst.
.jpg)
oryginalny tekst
ABBYY FineReader

Cueiform (Open OCR)

Puma.NET

SimpleOCR


Znowu najlepiej poradził sobie ABBYY FineReader i znowu wymagał znacznie więcej czasu niż pozostałe programy. Tekst bardzo przypomina ten oryginalny. Jedynie parę wyrazów zostało źle rozpoznanych. Układ tekstu jest idealny.
Trochę gorzej poradziły sobie Cueiform oraz Puma.NET. Tekst został rozpoznany tak samo przez obydwa programy. Problem jaki napotkały programy to rozpoznanie lewego boku tekstu, ze względu na ciut większe naświetlenie oraz lekkie jego pochylenie. Pozostała część tekstu została rozpoznana prawie bezbłędnie. Układ tekstu jest i tu idealny.
Znowu najgorzej poradził sobie SipmleOCR. Pomimo braku możliwości rozpoznawania polskiego języka, program część tekstu rozpoznał, ale niestety układ tekstu jest nieodpowiedni. Część wyrazów na siłę rozpoznano jako angielskie. Dużym zaskoczeniem jest rozpoznanie wyrazów leżących po lewej stronie tekstu. Układ tekstu jest nieodpowiedni.
Test 3
Podniosłem trochę poprzeczkę - test polegał na rozpoznaniu pisma drukowanego w języku angielskim, umieszczonego w dodatku na kolorowym tle.
Tekst pochodzi z ulotki reklamującego funkcję Instant Boot, dostarczanego razem z płytą główną firmy ASRock.
.jpg)
oryginalny tekst
ABBYY FineReader

Cueiform (Open OCR)

Puma.NET

SimpleOCR


W tym teście ładnie poradziły sobie ABBYY FineReader, Cueiform oraz Puma.NET, choć nie tak dobrze jak w poprzednich testach. Tekst został w każdym przypadku dosyć dobrze rozpoznany. Co ciekawe Finereader dodał nawet odpowiedniego koloru tło, ale praktycznie tylko pod tekstem, co niezbyt ładnie wygląda. Program starał się także dodać zdjęcia, co nie do końca mu się udało. Jak się nietrudno domyślić rozpoznawanie i tym razem wymagał trochę więcej czasu.
Dzieło Cueiform'a wygląda bardzo estetycznie – jest zachowana budowa tekstu, a nawet dodane jest zdjęcie (a raczej jego kawałek). Efekt pracy programu Puma.NET odstaje tylko od oryginału praktycznie ułożeniem i brakiem obrazków. Obydwa programy wymagał dosyć mało czasu.
Pomimo obsługi języka angielskiego program SimpleOCR znowu sobie nie poradził z rozpoznaniem tekstu. Program doszukiwał się znaków w kawałkach liter oraz w obrazkach, co niezbyt mu wyszło na dobre. Tylko pojedyncze wyrazy są dobrze rozpoznane – reszta to jakiś ciąg znaków niemających ze sobą nic wspólnego. Bardziej trafnym zastosowaniem dla tego programu było by szyfrowanie, a nie rozpoznawanie tekstu :)
Test 4
Nie samym polskim i angielskim człowiek żyje. Dorzuciłem do rozpoznania zwykły, drukowany tekst w języku rosyjskim z elementami alfabetu łacińskiego. Został on wzbogacony o parę obrazków. Dodatkowo utrudnieniem był naświetlony prawy bok i prześwitujący pod spodem tekst.
Tekst pochodzi z instrukcji do płyty głównej ASRock.

oryginalny tekst
ABBYY FineReader

Cueiform (Open OCR)

Puma.NET

SimpleOCR


I w tym teście bardzo dobrze poradził sobie ABBYY Finereader i jak w poprzednich testach wymagał trochę więcej czasu. Co prawda jest kilka błędów, ale są raczej kosmetyczne. Układ tekstu jest taki jak w oryginale. Obrazki zostały poprawnie dołączone, a jedynie czego brakuje to linii. Co ciekawe program poradził sobie z bardziej naświetlonym prawym bokiem.
Cueiform i Puma.NET poradziły sobie dosyć dobrze, ale w ich wynikach jest znacznie więcej błędów – dużo z nich także pochodzi od rozpoznawania tylko języka rosyjskiego. Obrazki są tak samo dobrze umieszczone, ale i tu brakuje linii. Bardziej naświetlony bok także został rozpoznany.
SimpleOCR ze względu na brak opcji rozpoznawania języka rosyjskiego, znowu nie rozpoznał poprawnie tekstu. Wynik jego pracy znowu przypomina ciąg losowych znaków.
Testy ekstremalne
Test ekstremalny 1
Pierwszy z testów ekstremalnych. Założenie testu było następujące – ktoś podczas próby rozpoznawania pomylił się i podał angielski tekst do rozpoznania obrócony o 90°.
Tekst pochodzi z instrukcji dołączonej do zasilacza firmy OCZ.

oryginalny tekst
ABBYY FineReader
.jpg)
Cueiform (Open OCR)

Puma.NET

SimpleOCR


Nadzwyczajnie dobrze poradził sobie ABBYY Finereader. Program jest na tyle „inteligentny”, że obrócił sobie tekst i rozpoznał go bezbłędnie. Jedyne zastrzeżenia można mieć do nierozpoznanego obrazka. Tu należą się brawa dla programistów! Jak to bywa w życiu – nie ma róży bez kolców, a kolcami w tym teście okazał się czas. Jest on nieporównywanie większy w porównaniu do innych programów, ale musimy to przeboleć.
Na drugim (bardzo odległym) miejscu znajdują się Cueiform oraz Puma.NET. Tekst nie został rozpoznany, ale na pocieszenie dodam, że programy rozpoznały część loga i umieściły je w poprawnym miejscu. Wyniki obydwu programów są prawie identyczne.
Najgorzej poradził sobie SimpleOCR. Nic nie rozpoznał poprawnie – nawet obrazka. To co program rozpoznał to prawie ciąg losowych znaków.
Test ekstremalny 2
Drugi z testów ekstremalnych. Specjalnie na potrzeby tego testu, próbka nie jest skanowana – została od razu zapisana w edytorze graficznym jako plik JPG. Próba polegała na rozpoznaniu fragmentów tekstu maszynowego, w języku polskim, poobracanych względem siebie. Dodatkowo tekst był zapisany różnymi czcionkami, różnej wielkości. Żeby nie było za łatwo, odwróciłem kolory.

oryginalny tekst
ABBYY FineReader

Cueiform (Open OCR)
pusta kartka
Puma.NET
pusta kartka
SimpleOCR


Test był dla wszystkich programów zbyt wymagający. Jedynie ABBYY Finereader próbował coś rozpoznać na obrazku. Obrócił tak próbkę, aby rozpoznać cokolwiek - i rozpoznał jedynie jedną linijkę tekstu. Reszta to błędne wyniki.
Cueiform oraz Puma.NET nic nie rozpoznały, co obrazuje biała kartka, a SimpleOCR wyświetlił komunikat, że nie da się rozpoznać tekstu.
Ciężko skomentować czasy rozpoznawania tekstu, ze względu na słabe wyniki.
Test ekstremalny 3
Trzeci z bardziej wyrafinowanych testów. Początkowo miał tu być test rozpoznawania pisma odręcznego z mojego zeszytu (a nie piszę zbyt ładnie), ale żaden program nie umiał sobie poradzić. Poprzeczkę minimalnie obniżyłem i dałem programom do rozpoznania kartkę z odręcznie napisanym (drukowanymi literami) przeze mnie tekstem (nie musicie mi mówić, że okropnie pisze :) ).
.jpg)
oryginalny tekst
ABBYY FineReader

Cueiform (Open OCR)

Puma.NET

SoftWriting


Znowu test okazał się dla programów zbyt wymagający. Wszystkie programy, ani kawałka tekstu nie rozpoznały poprawnie. Nawet program SoftWriting po nauce mojego pisma, nie zdał testu poprawnie.
Komentarz czasu rozpoznawania tekstu jest raczej zbędny, gdyż wszystkie programy nie poradziły sobie.
Test ekstremalny 4
Test ostatni, najbardziej wymagający - z założenia żaden program nie powinien go ukończyć. Test polegał na rozpoznaniu tekstu, a raczej zniekształconych liter – tak zwanej captchy (zniekształcony obrazek, mający na celu ograniczenie wykonania czegoś drogą automatyczną – przez komputer) Oczywiście i tu specjalnie na potrzeby testu, próbka tekstu została bezpośrednio dostarczona w pliku JPG – bez operacji skanowania.
Próbka pochodzi z hasła „captcha” w Wikipedii (tu).

oryginalny tekst
ABBYY FineReader
.jpg)
Cueiform (Open OCR)
pusta kartka
Puma.NET
pusta kartka
SimpleOCR


Jak widzimy, programy sobie nie poradziły odpowiednio z próbką. Jedynie coś wygenerował ABBYY Finereader oraz SimpleOCR. Wyniki się nie zgadzają, ale można powiedzieć że minimalnie lepiej poradził sobie SimpleOCR, który źle rozpoznał kolejne litery po „S”. ABBYY Finereader poprawnie odczytał „S” a reszty nawet nie ruszył. Pozostałe programu – Cueiform oraz Puma.NET – oddały pustą kartkę, bez wyników.
Co do czasu to i tu ciężko o komentarz, gdyż wszystkie programy sobie nie poradziły poprawnie.
Podsumowanie
Jak widać rozpoznawanie tekstu przez komputer stoi na nie takim niskim poziomie, jak by się mogło wydawać. Gdy tekst nie ma jakichś udziwnień, to szansa na bezbłędne rozpoznanie jest duża. Gdy jednak tekst do rozpoznania ma jakieś utrudnienia, na przykład w postaci złego ułożenia tekstu, czy zniekształcenia, szanse na poprawne rozpoznanie maleją.
Niewątpliwie najlepiej poradził sobie program ABBYY Finereader. Jest to zaletą niewątpliwie ciągłego dopracowywania produktu (o czym świadczy już 10 wersja tej aplikacji), oraz tego, że jest płatna. Pozostałe programy są w tyle (a nawet bardzo daleko jak w przypadku programu SimpleOCR/SoftWriting), ze względu na podejście do zagadnienia jako ciekawostka, a nie jako programy walczące o pozycję na komercyjnym rynku. Dla programów Cueiform oraz Puma.NET, należą się brawa za dosyć dobre wyniki w testach zwykłych. Oba programy prawdopodobnie korzystają z tego samego darmowego silnika, jakim jest Open OCR. W niektórych testach ich wyniki są ciut za produktem firmy ABBYY. Jeżeli zaś chodzi o czas operacji, to jest on nieporównywalnie krótszy porównaniu do konkurenta. Ich niewątpliwą zaletą jest cena... a raczej jej brak, ponieważ programy są darmowe.
Program SimpleOCR/SoftWriting raczej nie ma szansy zaistnienia w naszym kraju ze względu na poważną wadę jaką jest mała ilość obsługiwanych języków (w tym brak polskiego). Program jest także słabo dopracowany.
Na rynku jest wiele więcej programów OCR, ale niestety są płatne, a ich autorzy nie udostępniają wersji trial, czy demo. Dzięki takiemu posunięciu klient jest zmuszony, albo kupować w ciemno, albo wybrać inny - już sprawdzony produkt.
Śmiało mogę polecić program ABBYY Finereader osobom, które wymagają takiego programu na dłuższą metę. Jeżeli natomiast szukacie czegoś darmowego i wasze zainteresowanie takim programem jest raczej amatorskie, polecam dwa programy – Cueiform oraz Puma.NET.
ABBYY FinereaderPlusy:
Minusy:
|
CueiformPlusy:
Minusy:
|
Puma.NETPlusy:
Minusy:
|
SimpleOCR/SoftWritingPlusy:
Minusy:
|





Komentarze
22W programach OCR liczy się przede wszystkim procent popełnionych błędów. Zawsze. Kropka.
Dalej można rozpatrywać zdolność interpretowania złożonych formatowań, typu ilustracje, tabele, skład wielokolumnowy oraz wygodę użytkowania.
Przy prędkości dzisiejszych procesorów najmniej istotny jest czas rozpoznawania. Tym bardziej, że odbiorcami benchmarka są raczej użytkownicy domowi a nie firmy. Nie ma znaczenia, że 2 minuty dłużej poczekam na rozpoznanie moich 15 kartek. Co innego, gdyby to miało być 5000 stron co dzień (hipotetycznie w jakiejś firmie).
Autor skupił się na wyeksponowaniu czasu. Fail.
Powinno być że jest dłużej i tyle
I też j/w powinien być procent błędów, bo innej 'kategorii' to nie ma
A do captcha stosuje się skrypty, nie zwykłe OCRy które mają za zadanie czytać głównie tekst drukowany :P
Ostatnie "Moja ocena" ale czego? Nie wiem, może to się samo robi przy pisaniu mr, ale powinieneś dać punktacje dla każdego programu np. trudność w obsłudze itp
Dałem ci pomysł na forum, czy już wcześniej to planowałeś? ;D
4
np mogles zrobic test jeszcze tego
http://www.inftyproject.org/en/software.html#ChattyInfty
"czasami wymaga ciut więcej czasu"
Czasami...? ;>
Jest piątka ale taka trochę naciągana. Tak jak poprzednicy - bardziej powinieneś oceniać dokładność, a nie czas. Niezły język napisanej recki. :)
czego brakło:
-(tak już wspomnieli inni) ilości błędów
- rozpoznawanie tabelek
- oraz wzorów matematycznych, a szczególnie ułamki
- podsumowania
- ocena końcowa
naciągane 4
pozdro
P.S. Zapraszam do przeczytania mojej recenzji Flatout2 ;)
konwertuje dokumenty PDF, WORD, obrazy oraz posiada wsparcie dla 44 języków.