Kolejną bardzo istotną innowacją w stosunku do GT200 jest przebudowa dystrybutora (redystrybutora) wątków GigaThread. Wykorzystany tu dwupoziomowy scheduler został usprawniony przede wszystkim pod kątem podniesienia przepustowości, prędkości przełączania (fast context switching), jednoczesnej pracy na kilku aplikacjach (concurent kernel execution), oraz poprawienia dystrybucji całych bloków wątków przekazywanych dalej do procesorów SM i specjalizowanych „rozdzielaczy” warp.
Redukcja czasu przełączania pomiędzy zasobami znajdującymi się w potoku do 25 micro sekund przekłada się według producenta na 10-krotne przyspieszenie w stosunku do dystrybutora GigaThread poprzedniej generacji. W praktycznym użytku ma to przynieść skrócenie czasu przełączenia z jednego typu pracy na inny (np. z renderowania grafiki na obliczenia PhysX).
Architektura instrukcji PXE
Nowa architektura instrukcji PXE drugiej generacji (Parallel Thread eXecution) to niskopoziomowa maszyna wirtualna umożliwiająca efektywniejszą pracę układu w charakterze procesora wątkowego. Instrukcje PTX są tłumaczone przez sterownik na rozkazy zrozumiałe przez warstwę sprzętową. Celem zastosowania PTX-a jest przede wszystkim opracowanie wieloplatformowego translatora, uzyskanie jak największej wydajności GPU w obliczeniach równoległych (aplikacje uprzednio skompilowane), obsługę kompilatorów C, C++, Fortran czy też poprawę skalowalności użycia GPU w powyższych obliczeniach na bazie od kilku do jak największej ilości rdzeni połączonych równolegle.

PTX w wersji 2.0 wprowadza wiele nowych rozwiązań, które mają za zadanie znacznie usprawnić programowalność układu, jego dokładność oraz wydajność. Dotyczy to m.in. 32-bitowej precyzji zgodnej z normami IEEE, zunifikowanej przestrzeni adresowej dla wskaźników i zmiennych, 64-bitowego adresowania, czy też nowych instrukcji dla API OpenGL i DirectCompute.
Najważniejszą zmianą w stosunku do układów poprzedniej generacji, dzięki 40-bitowej zunifikowanej przestrzeni adresowej, jest jednak wspomniana obsługa interpretatora języka C++. Usprawnione sprzętowe przewidywanie skoków umożliwia teraz także, dla rozbieżnych wątków, efektywniejsze wykonywanie krótkich segmentów kodu bez wykonywania w tym czasie zbędnych rozgałęzień (no branching operations).
Podsystem ROP a usprawniony antyaliasing
Kolejną jednostką, która od czasu GT200 przeszła znaczący „facelifting”, jest Render Out Pixel, w skrócie znany jako ROP. Jak już wspominaliśmy w strukturze układu GF100 znajduje się 6 osobnych partycji modułów renderujących, zawierających po 8 jednostek przetwarzania. Łączna ich liczba, w zależności od konfiguracji danego układu, może więc wynosić od 48 do 40 jednostek. Dzięki dużej liczebności oraz zwiększeniu ich bazowej przepustowości, każda z nich jest w stanie przepuścić stałoprzecinkowy, 32-bitowy piksel na cykl zegarowy, zmiennoprzecinkowy FP16 na dwa cykle lub FP32 raz na cztery cykle. Duży wpływ na wydajność tej jednostki ma także optymalizacja operacji atomowych, powodująca zauważalne przyspieszenie wykonywania instrukcji – w stosunku do GT200 aż 20-krotnie (dla operacji pod tym samym adresem) i 7,5-krotnie (dla operacji w dalszych regionach struktury pamięci układu GF100).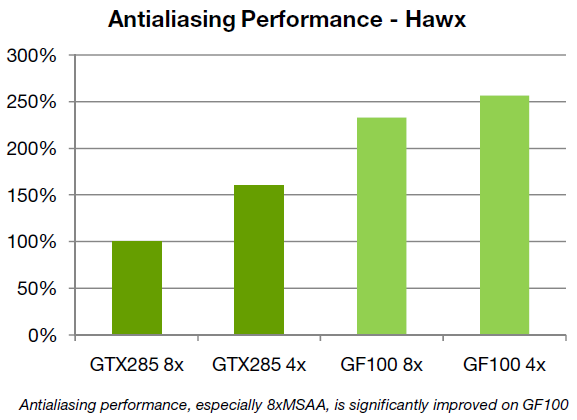
Usprawnienia w jednostkach ROP spowodowały podniesienie potencjału wygładzania krawędzi. Karta jest w tym elemencie renderingu od 1,5 do 2,5 razy szybsza od GT200 w trybach MSAA x4 oraz x8. Ponad 40 jednostek renderujących można będzie także wykorzystać dla nowego trybu 32x Coverage Sampling Antialiasing (w skrócie CSAA), oferującym przy niewiele większym obciążeniu od MSAA x8 znacznie lepsze efekty jakościowe wygładzanych krawędzi w środowisku DX10 i DX11. 
Rozbudowana technika alpha-to-coverage, wykorzystująca aż 32 próbki, będzie szczególnie przydatna do wygładzania krawędzi scen na których znajduje się np. mnóstwo liści, a z którymi nie radziły sobie do końca tradycyjne metody MSAA.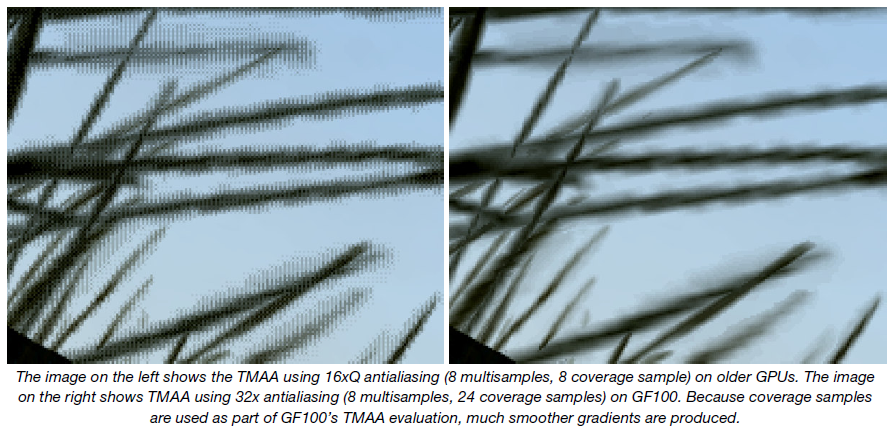
Co więcej, w środowisku DX9, które ze względu na ograniczenia samego API nie jest w stanie podczas antyaliasingu optymalnie wykorzystać przezroczystości, tryb CSAA 32x będzie również możliwy do zastosowania. Wszystko za sprawą przekonwertowania kodu shadera z Transparency Multisampling (TMAA) na użycie dodatkowych 24 próbek alpha-to-coverage zgodnych z CSAA.




