
Prezentujemy relację z GPU Technology Conference 2012, która odbyła się pod znakiem Keplera.
Niedawno w San Jose w Kalifornii odbyła się już trzecia edycja konferencji GPU Technology Conference (GTC), które tak naprawdę jest potężnym forum technologicznym poświęconym profesjonalnemu wykorzystaniu mocy obliczeniowej układów GPU. W konferencji, podobnie jak w przednich latach uczestniczyło kilka tysięcy programistów, deweloperów, naukowców, analityków i dziennikarzy z całego świata – w tym, również i nasza redakcja. Niemniej, o ile poprzednie dwie edycje konferencji poświęcone były przede wszystkim profesjonalnej grafice 3D i w mniejszym stopniu zaawansowanym obliczeniom realizowanym za pomocą kart graficznych, tak teraz tematami przewodnim był obliczenia HPC (ang. High Performance Computing), wirtualizacja układów graficznych, obliczenia w chmurze i przede wszystkim premiera obliczeniowej architektury Nvidia Kepler.
Oczywiście, trudno w krótkiej relacji opisać choćby tylko najciekawsze wydarzenia. Nie na wszystkich dało się nawet być. Dość wspomnieć, że w jednym dniu konferencji odbywało się kilkadziesiąt sesji na różne tematy, z czego kilkanaście prowadzonych było jednocześnie. Wzorem poprzednich lat wprowadzeniem do najważniejszej tematyki dnia były tak zwane keynotes – sesje plenarne, na których prezentowane były w skrócie najważniejsze lub zdaniem organizatorów najciekawsze pod względem tematycznym wydarzenia bądź prezentacje.
Obliczeniowa premiera Keplera
Nie ulega wątpliwości, że najważniejszym wydarzeniem związanym z tegoroczną edycją GTC 2012 była premiera obliczeniowej wersji układu Kepler o kodowej nazwie GK110. Na rynku obecna jest już od marca graficzna wersja układu Kepler oznaczona symbolem GK104, która znalazła się w kartach graficznych GeForce GTX 680, 670 i dwuukładowej 690, niemniej obliczeniowa wersja kości, wykorzystuwana w akceleratorach obliczeniowych Nvidia Tesla, różni się w znaczący sposób od jej graficznego odpowiednika.


Premiera obliczeniowej architektury Kepler, następcy dotychczasowej architektury Fermi, i nowego układu GK110 miała miejsce podczas pierwszego keynote’u prowadzonego przez współzałożyciela i dyrektora generalnego Nvidii – Jen-Hsun Huanga.

Najważniejsze, prezentowane przez Jen-Hsun Huanga elementy architektury Kepler – SMX, Hyper-Q i Dynamic Parallelism.
Pierwszym elementem różniącym Keplera od jego poprzednika, układu Fermi, są nowej generacji procesory strumieniowe SMX (Stream Multiprocessors eXtended). W ich skład wchodzi, nie jak poprzednio 32 rdzenie CUDA, lecz w Keplerze na jeden moduł SMX jest ich aż 192. Pełna implementacja architektury Kepler GK110 liczy 15 modułów SMX (będą też wersje zawierające 13 i 14 jednostek SMX) i sześć 64-bitowych kontrolerów pamięci, co łącznie daje 2880 procesorów CUDA – niemal dwa razy więcej niż GK104, w którym jest ich „tylko” 1536. Dzięki temu układ GK110 jest jednym z największych obecnie produkowanych seryjnie układów scalonych. Liczy on 7 miliardów tranzystorów.

Porównanie liczby rdzeni CUDA przypadającej na jeden procesor strumieniowy w architekturze Fermi i Kepler.
Procesory strumieniowe SMX są oczywiście obecne w najnowszych kartach graficznych z serii GeForce GTX 6xx, ale elementami różniącymi pod względem funkcjonalnym architekturę GK104 od GK110 są technologie Hyper-Q i Dynamic Parallelism. Obie nie są obecne w graficznej wersji układu Kepler.

Hyper-Q pozwala na uzyskanie większej liczby symultanicznych połączeń między CPU a GPU
Technologia Hyper-Q, pozwala na symultaniczną współpracę wieloprocesorowych jednostek centralnych z jednym układem GPU w taki sposób, aby zwiększyć wydajność przetwarzania danych przez GPU, eliminując jednocześnie cykle oczekiwania procesora. W technologii Hyper-Q konstruktorzy układu Kepler zwiększyli całkowitą liczbę połączeń pomiędzy systemem i układem GK110, przez co możliwe jest jednoczesne ustanowienie aż 32 sprzętowo zarządzanych połączeń, którymi przesyłane są dane między CPU a GPU. Warto dodać, że w układach Fermi wykorzystywanych w kartach Tesla, dostępne było tylko jedno takie połączenie. Innymi słowy, Hyper-Q pozwala na ustanowienie oddzielnych, niezależnych połączeń między wieloma rdzeniami CUDA, podczas przetwarzania wielowątkowego w taki sposób, że każdy wątek ma dostęp do „swoich własnych” rdzeni CUDA.
Z kolei technologia Dynamic Parallelism pozwala na zaimplementowanie większej liczby algorytmów przetwarzania równoległego w programach przygotowywanych przez programistów, a wykonywanych na GPU, ponieważ istnieje możliwość natychmiastowego dołączania dodatkowych zadań wynikających bezpośrednio z rezultatów otrzymanych przed chwilą przez GPU bez udziału CPU. W ten sposób można w trakcie pracy programu dołączyć dodatkowe wątki programu, szybciej realizować równoległe obliczenia w zagnieżdżonych pętlach o różnych wartościach zbieżności, czy kontrolować warunki zrównoleglenia wykonywanych po kolei zadań – i to wszystko bez udziału centralnego procesora.

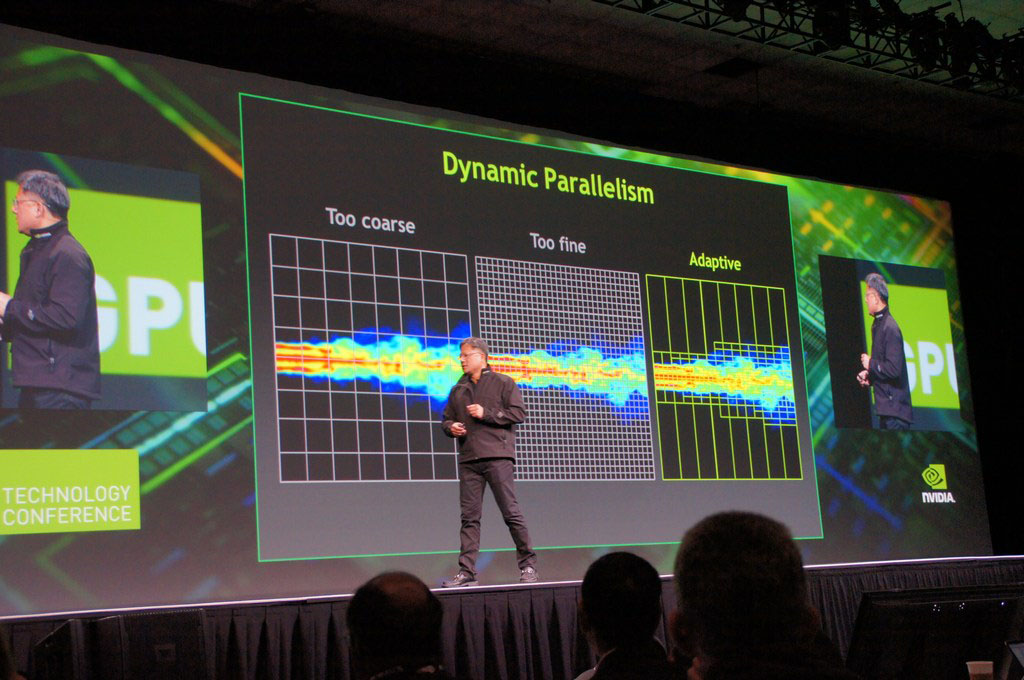
Działanie technologii Dynamic Parallelism pozwala na dynamiczne dostosowanie równoległych obliczeń do przetwarzanego aktualnie zadania.

Na bazie układu GK110 produkowany będzie akcelerator obliczeniowy Tesla K20. Tesla K10 korzysta zaś z dwóch układów GK104. Mocniejsza Tesla K20 dostępna będzie dopiero pod koniec bieżącego roku.




