




ATi R500
Po 18 miesiącach od premiery swojego ostatniego procesora graficznego X800 (R420) i 3 miesiące po wydaniu przez nVidię drugiego już GPU zgodnego z Shader Model 3.0 (G70), inżynierowe z firmy ATi w końcu mogli oddać do użytku swoje najnowsze dzieło - chip o kodowym oznaczeniu R500.
W dzisiejszych czasach głównym elementem określającym nowoczesność i stopień zaawansowania grafiki jest zgodność z ShaderModel 3.0 (DirectX 9c), którą ATi R500 oczywiście już dysponuje. To oznacza, że po ponad półtora roku dominacji nVidii w tej dziedzinie, ATi nareszcie może iść ramię w ramię ze swoim największym konkurentem.
Czy klasyfikowanie kart na podstawie obsługi określonego Modelu Cieniowania jest/było słuszne, tego raczej żaden użytkownik-gracz nie będzie pewien. Zwłaszcza, że oba te modele mieściły się przecież w obrębie jednej specyfkacji DirectX : 9b lub 9c (Microsoft nie chciał ich nawet rozróżnić jako 9.1) - czy taka subtelna różnica może oznaczać coś nadzwyczajnego dla zwyłego gracza? Czy zapewni mu więcej zabawy i emocji podczas gry? Na to pytanie chyba nie musimy już sobie odpowiadać.

Co do jednego jesteśmy natomiast pewni - SM 3.0 stał się potężnym narzędziem walki marketingowej. Co gorsza, ci dwaj najwięksi producenci procesorów graficznych zaczęli wchodzić w 'układy' z producentami gier, optymalizując niektóre z nich pod swoje chipy.
Na szczęście w kolejnej wersji DirectX 10 Microsoft położy kres szybkiemu tempu wprowadzania coraz to nowych funkcji w kartach graficznych. Była to jedna z wielu rewelacji na temat nowego API kart graficznych ogłoszona przez Rudolpha Balaza, menadżera produktu Microsoftu, podczas tegorocznej konferencji Professional Developers Conference. Więcej na ten temat pisaliśmy już we wrześniowym artykule.
Oczywiście zgodność z DirectX 9c to nie jedyna cecha nowych procesorów ATi. Inżynierowie wymyśli jeszcze kilka technologii, dzięki którym karty Radeon X1000 mają bez kompleksów rywalizować z najnowszymi GeForce'ami 7800. Najważniejsze z nich to:
- technologia wykonania 90 nm
- nowa, ultrawątkowa architektura (Ultra-Threaded Shader Engine)
- pierścieniowy kontroler pamięci
- CrossFire - technologia łączenia dwóch kart (odpowiednik SLI u nVidii)
- Avivo - zaawansowany obraz i wideo
Każdą z nich po krótce omówimy w tym artykule.
Na początek porównanie możliwości czterech najsilniejszych chipów : obecny rywal GeForce 7800, oraz dwa starsze. Widać wyraźnie, że ATi nadrabiało poważne tyły w stosunku do swojej konkurencji. Dopiero teraz zaoferowało rozwiązania, które nVidia wprowadzała kolejno w tamtym i w tym roku.
Wydajność 'teoretyczną' karty przyjęło się oceniać na podstawie liczby potoków renderujących i częstotliwości taktowania GPU, oraz liczby jednostek Vertex Shader. Przypomnijmy, że w swojej specyfikacji G70 nVidia rozróżniła 'potoki pixeli' i 'potoki renderujące piksele'. Tych pierwszych GPU nVidii ma aż 24, natomiast rzeczywistych potoków renderujących" jest 16, a więc tyle samo co w nowym X1800.
| nVidia NV40 GeForce 6800 | nVidia G70 GeForce 7800 | ATi R400 Radeon X850 | ATi R500 Radeon X1800 | |
| data wydania | 04'2004 | 06'2005 | 05'2004 | 10'2005 |
| technologia wykonania | 130 nm | 110 nm | 130 nm | 90 nm |
| liczba tranzystorów | 222 mln | 302 mln | 160 mln | 320 mln |
| kontroler pamięci | 256-bit GDDR | 256-bit GDDR | 256-bit GDDR | 256-bit GDDR |
| Pixel procesor | ||||
| Shader Model | 3.0 | 3.0 | 2.0b | 3.0 |
| potoki Pixel Shader | 16 | 24 | 16 | 16 |
| potoki ROP renderujące | 16 | 16 | 16 | 16 |
| maksymalna liczba Z w cyklu | 32 | 32 | 16 | 16 |
| liczba tekstur w cyklu | 16 | 16 | 16 | 16 |
| statyczne pętle i rozgałęzienia | tak | tak | tak | tak |
| dynamiczne pętle i rozgałęzienia | tak | tak | nie | tak |
| multiple render target | tak | tak | tak | tak |
| floating-point render target | tak | tak | tak | tak |
| techniki filtrowania | dwu/trójliniowe anizotropowe | dwu/trójliniowe anizotropowe | dwu/trójliniowe anizotropowe | dwu/trójliniowe anizotropowe miejscowe anizo |
| maksymalny poziom filtrowania anizo | x 16 | x 16 | x 16 | x 16 |
| Vertex procesor | ||||
| Shader Model | 3.0 | 3.0 | 2.0b | 3.0 |
| liczba jednostek Vertex | 6 | 8 | 6 | 8 |
| statyczne pętle i rozgałęzienia | tak | tak | tak | tak |
| dynamiczne pętle i rozgałęzienia | tak | tak | nie | tak |
| odczyt tekstur z vertex shader | tak | tak | nie | tak |
| teselacja | nie | nie | nie | nie |
| FSAA, HSR, HDR | ||||
| algorytmy FSAA | multipróbkowanie, obracaną siatką | multipróbkowanie, obracaną siatką, przeźroczyste | multipróbkowanie, obracaną siatką, czasowe | multipróbkowanie, obracaną siatką, czasowe, przeźroczyste, |
| próbkowanie FSAA | 2/4/6/8 | 2/4/6/8 | 2/4/6 | 2/4/6 |
| HSR - usuwanie niewidocznych | tak | tak | tak | tak |
| kompresja tekstur, bufora-Z | tak | tak | tak | tak |
| szybkie czyszczenie bufora-Z | tak | tak | tak | tak |
| HDR | tak | tak | tak | tak |
| obsługa OpenEXR HDR | tak | tak | nie | tak |
| procesor video | tak | tak | nie | tak |
Radeony X1300, X1600, X1800
Najmocniejsze karty z serii X1800 są wyposażone w procesor R520, z wbudowanym nowym koderem TV - Xilleon, ze sprzętową akceleracją kodowania H.264, oraz obsługą CrossFire, czyli odpowiednikiem SLI, do łączenia dwóch kart. Cechą szczególną R520 jest nowy kontroler pamięci, z wewnętrzną, 512-bitową szyna. Zewnętrznie szyna do pamięci ma szerokość 256-bitów.
Radeon X1800 ma 16 potoków PixelShader i 8 jednostek vertex shader.
olbrzymia karta Radeon X1800 XL (23 cm długości)

W kartach X1600 umieszczany jest procesor RV530. Ma te same cechy co 520, z tą różnicą, że dysponuje już tylko 12 potokami PixelShader i 5 jednostkami vertex shader, oraz operuje na o połowę węższej szynie - wewnętrznie tylko 256-bit i zewnętrznie 128-bit. Cechą szczególną X1600 ma być dodatkowo bardzo niski pobór energii, rzędu 40W.
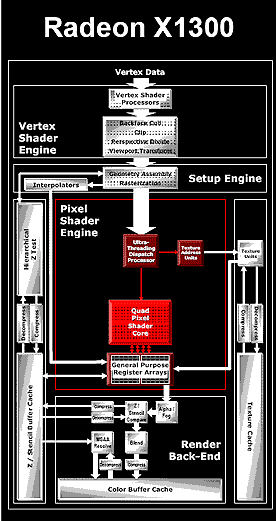
RV515 montowany na kartach X1300, to najsłabszy chip przeznaczony na rynek 'low-end'. Jego główną cechą będzie sprzętowa akceleracja kodowania H.264 i obsługa HDCP.
karta MSI Radeon X1300 Pro

Wszystkie karty z serii X1000 mają wsparcie dla technologii CrossFire, oraz korzystają z dobrodziejstw ATi Avivo.
| X1300 Hyper Memory | X1300 | X1300 Pro | X1600 Pro | X1600 XT | X1800 XL | X1800 XT | |
| nazwa kodowa GPU | RV515 | RV530 | R520 | ||||
| technologia wykonania | 90 nm | 90 nm | 90 nm | ||||
| liczba procesorów vertex | 2 | 5 | 8 | ||||
| liczba potoków PixelShader | 4 | 12 | 16 | ||||
| max. liczba wątków | 128 | 128 | 512 | ||||
| zegar GPU | 450 MHz | 450 MHz | 600 MHz | 500 MHz | 590 MHz | 500 MHz | 625 MHz |
| zegar pamięci DDR | 500 MHz | 250 MHz | 400 MHz | 400 MHz | 690 MHz | 500 MHz | 750 MHz |
| szyna do pamięci | 32-bitowa 64-bitowa | 128- bitowa | 128- bitowa | 128- bitowa | 128- bitowa | 256- bitowa | 256- bitowa |
| Ring Bus | brak | brak | brak | 2x128-bit | 2x128-bit | 2x256-bit | 2x256-bit |
| inne technologie | Avivo CrossFire | Avivo CrossFire | Avivo CrossFire | ||||
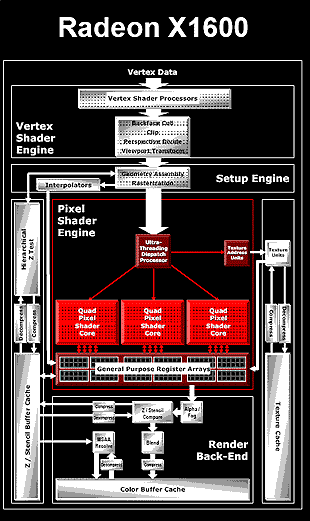
Ultra-Threaded Shader Engine
ATi rozłożyło ciężar obliczeń na różne elementy układu. Efektem tego jest architektura wielowątkowa (multi-threaded) lub mówiąc językiem ATI, Ultrawątkowa (Ultra-Threaded Architecture). Nazwa tej technologii brzmi podobnie do intelowskiej Hyper-Threading (współbieżność wielowątkowa) i cechuje ją także podobny cel, czyli jak najwydajniejsze wykorzystanie zasobów obliczeniowych procesora i zminimalizowanie czasu, w którym jego narzędzia wykonawcze spoczywają bezczynnie.
architektura R520
Istnieją pewne zbieżności nie tylko między architekturą Radeona X1000 (R500), Radlona 9000 (R300) i Radeona X800 (R400), ale także z nową architekturą zastosowaną w Xbox 360 GPU.
Na przykład, GPU Radeona X1000 wyposażony jest w zintegrowany inteligentny układ przełączający, tak zwany Ultra-Threading Dispatch Processor, którego zadaniem jest rozkładanie ciężaru obliczeniowego pomiędzy czwórki procesorów pikselowych (każda czwórka składa się z czterech procesorów pikselowych, z których każdy jest w stanie przetwarzać shader dla bloku 2x2 piksele w pojedynczym cyklu zegara) a układy zajmujące się odwzorowaniem tekstur.
Ultra-Threading Dispatch Processor dzieli materiał pikselowy, który ma przetworzyć na małe wątki o rozmiarze 4x4 piksele. Jest także w stanie wykryć momenty przestoju procesorów pikselowych w czwórkach i przypisać im nowe zadania. Jeśli dalsze wykonanie shadera wymaga danych, które nie są jeszcze gotowe, procesor arbitrażowy zatrzymuje dany wątek aż do momentu, w którym napłyną dane. Zwalania on tym samym ALU umożliwiając realizację innych wątków i maskując opóźnienie samplowania tekstur, na przykład tych przechowywanych w cache lub pamięci. Według ATI, architektura ta pomaga osiągnąć wydajność procesorów pikselowych dla każdego shadera na poziomie 90% .
Szybkie przełączanie pomiędzy wątkami wymaga przechowywania pośrednich danych dla każdego z nich. ATI korzysta ze specjalnego rejestru (General Purpose Register Array) bardzo wydajnie połączonego z procesorami pikseli, tak jak to miało miejsce w przypadku poprzednich GPU ATI.
Nowe rozwiązania ATI, zgodne ze standardem Shader Model 3.0, w pełni obsługują pętle, rozgałęzienia, skoki i podprogramy. Kontrola przepływu pomaga im wykonać teoretycznie nieskończoną liczbę mini-programów shaderów. Rodzina procesorów Radeon X1000 wykonuje wszystkie operacje w 128 bitowym formacie zmiennoprzecinkowym, który minimalizuje możliwość pojawienia się skumulowanych i pogarszających jakość obrazu błędów związanych z zaokrąglaniem wyników obliczeń.
Powiększyła się liczba równocześnie wykonywanych wątków kodowych, ale rozmiar każdego z wątków został zmniejszony do rozmiaru 4x4 piksele. Pomaga to osiągnąć wyższą wydajność przy dynamicznym rozgałęzianiu / skokach.
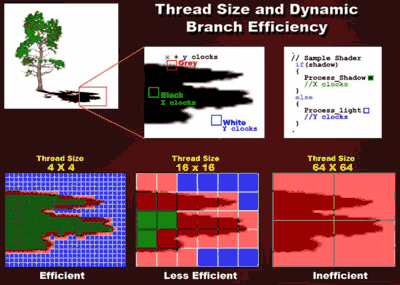
Korzyści wynikające z podejścia ATI są oczywiste: wydajność dynamicznego rozgałęziania/skoków pogarsza się w znaczącym stopniu wraz ze wzrostem wielkości wątku i staje się nieopłacalna w przypadku wątków o rozmiarze 64x64 piksele. Wyższy model, Radeon X1800 (R520), jest w stanie wykonać do 512 wątków kodu shader równocześnie, podczas gdy niższe modele ograniczone są 128 równoczesnymi wątkami.
Kolejną interesującą cechą Radeona X1800 jest specjalny, dedykowany układ zajmujący się przewidywaniem skoków, wykonywaniem określonych gałęzi. Dzięki wykonywaniu jednej instrukcji sterowania przepływem danych (warunki, pętle, podprogramy) na cykl zegara, układ ten jest w stanie zredukować obciążenie głównego ALU. Shadery, które używają instrukcji sterowania przepływem danych wykonywane są w mniejszej niż zwykle liczbie cyklów. Może to nieść ze sobą znaczny przyrost wydajności w przypadku wersji pixel shader 3.0 w porównaniu z rozwiązaniami nVidii.
Z racji tego, że współczesne gry komputerowe powszechnie wykorzystują pixel shader, ATI kładzie duży nacisk na wydajność GPU ze szczególnym jego uwzględnieniem. Pixel pipeline w GeForce 7 zostało także poprawione w porównaniu do poprzednich GPU nVidii.
Cel osiągnięto dzięki zwiększonej liczbie ALU. Każdy procesor pikselowy R520 wyposażony jest w 2 skalarne i 2 wektorowe ALU zdolne do wykonywania do 4 instrukcji w cyklu zegarowym (2 typy instrukcji ADD + modyfikator, 2 typy instrukcji ADD/MUL/MADD).
Nowy Radeon to także pierwszy GPU, w którym układy odpowiedzialne za texture-mapping (mapowanie tekstur) i texture addressing (adresowanie tekstur) komunikują się z procesorem shader, nie bezpośrednio, ale poprzez Ultra-Threading Dispatch Processor. Jest to jeszcze jednym środkiem optymizacji całego rdzenia graficznego, którego głównym celem jest ukrycie opóźnień w adresowaniu tekstur. Po prostu łatwiej jest koordynować wszystkie układy za pomocą jednego centrum kontrolnego.
ATI Technologies twierdzi, że całkowita wydajność R520 równa jest 83Gflopom, podczas gdy nVidia informuje, że G70 osiąga 165Gflopów. Wynik ten jest dwukrotnie większy od wydajności układu ATI, ale porównanie jest prawdopodobnie błędne. Prędkość GeForce 7800 GTX została zmierzona przy użyciu instrukcji MADD, a nie wiemy w jaki sposób wydajność swoich kart mierzyła ATI.
Procesory vertex Radeona X1000 zostały zaprojektowane w podobny sposób do architektury GeForce 7 nVidii. Każdy procesor składa się z dwóch układów, wektorowego i skalarnego, z taką różnicą, że procesor vertex G70 ma 32 bitowe ALU, podczas gdy w X1000 jest 128 bitowy. Cecha ta pozwala na emulowanie centralnego procesora na GPU.
Nowe procesory vertex potrafią wykonywać dwie instrukcje w jednym cyklu zegara. Zwykły shader może mieć długość 1024 instrukcji lub być teoretycznie nieskończony przy wykorzystaniu instrukcji kontroli przepływu. Oczywiście procesory vertex X1000 są w pełni zgodne ze specyfikacją Shader Model 3.0.
Teoretycznie, wydajność vertex shader X1800 XT powinna być dużo większa niż tego, w który wyposażona jest karta GeForce 7800 GTX, ponieważ jego procesor pracuje z dużo wyższą częstotliwością.
Pierścieniowy kontroler pamięci
ATI wyposażył swoje nowe procesory graficzne w zupełnie nowy, przerobiony kontroler pamięci. Wewnętrzna szyna pamięci X1800 ma topologię pierścieniową i składa się z dwóch 256 bitowych dwukierunkowych szyn pierścieniowych, natomiast X1600 z dwóch 128 bitowych szyn dwukierunkowych.
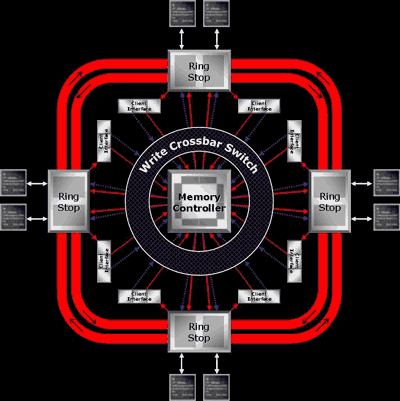
Szyny pierścieniowe otaczają kość, pomagają upraszczać i optymalizować wzajemne łączenie. Dzięki temu składniki układu mogą być połączone w najkrótszy sposób. W połączeniu z jednostką wykonawczą, rozwiązanie to minimalizuje opóźnienia i zniekształcenia sygnału podczas operacji zapisywania pamięci. Dzięki technologii pierścieniowej Radeony X1800 i X1600 mogą współpracować z pamięciami o wysokiej częstotliwości takim jak np. GDDR4, podczas gdy tradycyjna architektura nie byłaby w stanie ich obsłużyć ze względu na nie najlepiej skonstruowane łączniki wewnątrz GPU.
Pamięć połączona jest z szyną w miejscu tak zwanych przystanków pierścieniowych (Ring Stops). Istnieją 4 takie miejsca, każde z nich ma dwa 32 bitowe kanały dostępu. Dla porównania, pamięć Radeona X850 łączy się z kontrolerem za pomocą 64 bitowych kanałów. Każdy punkt Ring Stop może podać dane klientowi według instrukcji kontrolera pamięci.
Podsystem Ring Bus pracuje w bardzo prosty sposób. Klient wysyła zapytanie o dane do kontrolera pamięci, który jest umieszczony w centrum układu. Kontroler pamięci korzysta ze specjalnego algorytmu, aby określić priorytet każdego zapytania, nadając najwyższy status tym zapytaniom, które mają największy wpływ na wydajność. Następnie przesyła odpowiednie zapytanie do pamięci i wysyła dane wzdłuż szyny pierścieniowej (Ring Bus) aż do przystanku (Ring Stop) najbliższego pytającemu klientowi. Z Ring Stop dane docierają do klienta. Tak zwany Write Crossbar Switch znajduje się wokół kontrolera odpowiedzialnego za optymalny dostęp do pamięci. Nadzoruje on równy rozdział zapytań.
Algorytm operacyjny nowego kontrolera może być programowany przez driver, tak więc w przyszłości jego funkcjonowanie może zostać usprawnione. Co więcej, ATI ma teoretyczną szansę programowania kontrolera pod kątem określonych aplikacji i tworzenia odpowiedniego profilu w sterownikach Catalyst.
Cache stał się w pełni asocjacyjny, tzn. dowolna linia cache może przechowywać zawartość dowolnej lokacji w pamięci zewnętrznej.
Przy zachowaniu tej samej częstotliwości, cache asocjacyjny pracuje o wiele wydajniej niż bezpośrednio mapowany (direct-mapped cache). W związku z tym, nowa architektura ma duży zapas wydajności względem aplikacji, dla których niezmiernie ważna jest przepustowość pamięci grafiki podsystemu. Innymi słowy, Radeon X1000 ma spisywać się świetnie przy wysokich rozdzielczościach i/lub przy włączonym pełnoekranowym wygładzaniu i anizotropowym filtrowaniu.
Również technologia HyperZ została poprawiona. Użyto bardziej wyszukanego algorytmu do identyfikowania niewidocznych powierzchni, które mają być usuwane. ATI twierdzi, że nowy algorytm jest o 50% bardziej wydajny niż ten z Radeona X850.
Zauważmy, że mimo iż RADEON X1300 nie obsługuje ani szyny pierścieniowej (Ring Bus) ani programowalnego arbitra zapytań pamięci, wykorzystuje on inne techniki zaprojektowane z myślą o poprawie przepustowości pamięci kart z rodziny RADEON X1000.
HDR
Nowa generacja procesorów graficznych ATI w pełni obsługuje tryby wyświetlania 'high dynamic range', znane pod skrótem HDR. Jeden z trybów HDR był już dostępny w rodzinie procesorów Radeon X800, jednak cecha ta nie została dostatecznie doceniona przez twórców gier.
śliczne efekty HDR w demku Masaki Kawase

Standard OpenEXR z 16 bitowym odwzorowaniem kolorów, opracowany przez Industrial Light & Magic, stał się powszechnie używanym standardem w przemyśle filmowym, stosowanym do tworzenia efektów specjalnych w filmach. Twórcy gier pozostali jednak obojętni wobec niego. Przez długi czas Far Cry była jedyną grą, która obsługiwała OpenEXR. Mimo tego udogodnienia, w trybie HDR widoczny był olbrzymi spadek wydajności. Gra w rozdzielczościach wyższych niż 1024x768 była kompletnie niemożliwa. Co więcej, charakterystyka zastosowania HDR w architekturze nVidii NV40 sprawiła, że korzystanie z pełnoekranowego trybu antyaliasingu stało się niemożliwe. Kolejna karta, GeForce 7800 GTX, miała odpowiednią moc obliczeniową, pozwalającą na względnie komfortowe korzystanie z OpenEXR, jednak nie umożliwiała łączenia go z FSAA.
Podczas opracowywania nowej architektury ATI Technologies wzięła pod uwagę wcześniej nabyte doświadczenie, dzięki czemu RADEON X1000 wyposażony został w szeroką gamę funkcji wspomagających HDR, łącznie z wieloma, także dostosowalnymi do potrzeb użytkownika, formatami.
GPU Radlona X1000 pozwala na używanie HDR wraz z pełnoekranowym antyaliasingiem. Jest to niewątpliwie duży krok naprzód od momentu wprowadzenia GeForce 6/7, ale czy nowe GPU będą miały odpowiednią wydajność, aby zapewnić komfortową prędkość w nowych trybach HDR?
Wiemy jednak, dlaczego nowy układ R520, stosowany w wyższych modelach GPU ATI, jest bardziej złożony od G70 nVidii. Każda z powyżej opisanych innowacji w zakresie architektury wymagała swojej liczby tranzystorów w kości. R520 składa się z 320 milionów tranzystorów i mimo tego, że wyposażony jest tylko w 16 potoków pikseli - a nie 24 jak G70 - czyni z niego najbardziej złożony procesor graficzny dostępny na rynku.
Anizo, Antyaliasing i inne
Sekcja R500 odpowiedzialna za wygładzanie krawędzi i filtrowanie tekstur nadal nosi nazwę SMOOTHVISION HD. W tej materii nowy chip niewiele różni się od poprzednika. Najważniejszą nowością jest dodanie przez ATi wygładzania AA z przeźroczystością - na podobieństwo funkcji która znalazła się kilka miesięcy temu w G70 nVidii.
W sterownikach 5.10 znaleźliśmy do niej osobny 'włącznik', natomiast w najnowszych 5.11 został już przeniesiony do osobnej zakładki, razem z 'Supersampling' i 'Adaptive Antialiasing'. Ten ostatni algorytm przelicza jaka część renderowanych obiektów powinna być poddana 'AA' i wygładza tylko te piksele, które tego wymagają.
Do antyaliasingu X1000 używa algorytmów dwu-, cztero- lub sześcio-krotnego multipróbkowania pixeli, ale może dodatkowo używać także różnych wzorców próbek.
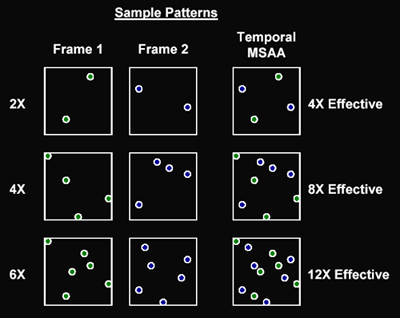
Tak samo jak w X800, nowe Radeony oferują także Temporal Anti-Aliasing - czyli czasowy Anti-Aliasing. To połączenie dwóch różnych wzorców próbkowania, które naprzemiennie stosowane są do kolejnych klatek obrazu. Zakładając, że obraz wyświetlany jest z szybkością większą niż 60 klatek na sekundę (warunek włączenia czasowego AA), czyli z osobna nieuchwytnymi dla oka ludzkiego, przy ustawieniu Temporal AAx2 renderowany obraz zobaczymy z efektywnym wygładzaniem AAx4, itd Demonstruje to obrazek poniżej.
W procesorach X1000 jest też 3Dc - metoda kompresji map wektorów normalnych. Kompresja ta - o współczynniku kompresji 4:1 - umożliwia zmniejszenie pliku z teksturą, (a więc także poprawienie wydajności poprzez oszczędzanie na przepustowości pamięci), lub zwiększenie szczegółowości takiej tekstury, czyli większy realizm obiektów na które nakładana jest "mapa normalnych". ATi opracowało i zaproponowało nową metodę kompresji 3Dc, bowiem dotychczasowe techniki kompresji tekstur DTXC i S3TC, były nieskuteczne w kompresji "map normalnych". Więcej informacji na temat tej technologii zamieściliśmy już podczas premiery Radeonów X800.












