![]() Podstawowe elementy współczesnej mikroarchitektury
Podstawowe elementy współczesnej mikroarchitektury
 Podstawowe elementy współczesnej mikroarchitektury
Podstawowe elementy współczesnej mikroarchitekturyPrzyjrzyjmy się teraz podstawowym cechom mikroarchitektury procesorów, wpływających na wydajność współczesnych jednostek centralnych. Pierwszą z nich jest potokowość, drugą superskalarność i związana z nią wielopotokowość, trzecią predykcja rozgałęzień programu, a czwartą wykonywanie rozkazów poza kolejnością.
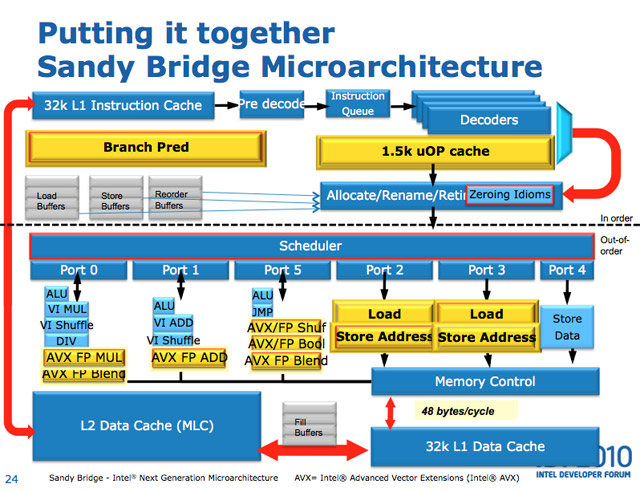
Mikroarchitektura procesorów Intel Sandy Bridge
Jak wiadomo, program komputerowy składa się z ciągu następujących po sobie poleceń (instrukcji) oraz zbioru danych, na których przeprowadza się poszczególne operacje. Procesor realizując program pobiera z pamięci operacyjnej kod i dane, przetwarza je i na końcu wysyła wyniki z powrotem do pamięci RAM lub innego urządzenia wyjściowego takiego jak karta graficzna czy dysk twardy. Jeżeli teraz przyjrzymy się przepływowi danych to można zauważyć, że wykonanie najprostszej operacji dodawania dwóch liczb (A+B) wymaga aż dziewięciu kroków lub inaczej, taktów zegara.
W pierwszym kroku instrukcja jest pobierana spod adresu wskazywanego przez tak zwany licznik rozkazów, w drugim jest dekodowana, w trzecim wykonywana. W wypadku wspomnianego dodawania (najprostszy program w asemblerze x86 realizujący to zadanie składa się z trzech linijek kodu – MOV AH,A; MOV AL,B; ADD AH,AL) jest to przesłanie danej A do rejestru AH. Później pobierany jest drugi rozkaz, czyli dana B przenoszona jest do drugiego rejestru AL (są to kolejne trzy kroki). Następnie pobierany jest trzeci rozkaz, który jest dekodowany i wykonywany, co kończy cykl przetwarzania z naszego przykładu – do liczby A dodawana jest liczba B, czyli zawartość rejestru AH zwiększona zostaje o liczbę znajdującą się w rejestrze AL – to kolejne trzy kroki.
Jak widać na wykonanie zaledwie jednej instrukcji programu (jej pobranie, zdekodowanie i wykonanie) potrzebne są przynajmniej trzy cykle zegara. Oznacza to, że dwie jednostki wykonawcze w każdym wykonywanym przez procesor kroku nie są obciążone pracą – np. przy dekodowaniu „nudzą się” odpowiednio moduł pobierający instrukcje oraz jednostka wykonawcza. Aby zwiększyć wydajność układu, wystarczy po prostu obciążyć w tym samym czasie dwie pozostałe jednostki zadaniami wykonywanymi „na zakładkę”. Wówczas, dla naszego przykładu, jednocześnie jednostka wykonawcza może realizować przesyłanie danej A do rejestru AH (MOV AH,A), moduł dekodujący dekodować będzie drugi rozkaz dotyczący pobrania danej B (MOV AL,B), a jednostka pobierająca pobierać będzie instrukcję dotyczącą zwiększenia zawartości rejestru AH (ADD AH,AL). Opisane tutaj udoskonalenie mechanizmu działania procesora nazywa się przetwarzaniem potokowym (ang. pipelining), a o układzie mówi się, że jest wykonany w architekturze potokowej.
Przedstawiona wyżej architektura nosi nazwę trójfazowej – mamy w niej trzy niezależne fazy wykonywania instrukcji w jednym potoku, czyli pobieranie, dekodowanie, wykonanie. Procesor potokowy korzystający z architektury trójfazowej przykładowy program wykonujący dodawanie liczb A+B będzie w stanie zrealizować w trakcie siedmiu cykli. Co ważne, w tym samym czasie mogą być również wykonane dwie z trzech faz instrukcji poprzedzających nasze dodawanie i dwie fazy z dalszej części programu. W sumie w ciągu siedmiu cykli zegara wykonanych zostanie 4 i 1/3 instrukcji. Przyśpieszenie szybkości przetwarzania danych jest spore – jedna instrukcja wykonywana jest średnio w 1,6 cyklu zegarowego, a nie w trzech.

Idea przetwarzania potokowego
Oczywiście, przetwarzanie potokowe nie zawsze przebiega tak sprawnie jak w naszym przykładzie. Często zdarza się, że cześć operacji (faz potoku) musi być wstrzymana ze względu na fakt wykorzystywania przez kolejne instrukcje programu tych samych rejestrów czy jednostek wykonawczych procesora, a także ze względu na powiązanie ze sobą instrukcji w taki sposób, że jedne instrukcje oczekują na dane, które są wynikami operacji realizowanych przez inne. Problem ten rozwiązuje się wydłużając potok wykonawczy. Na przykład w procesorach AMD Athlon 64 potok jest 15-etapowy, w układach Intel Core 2 Duo składa się on z 14 faz, a w kościach Intela z rdzeniem Sandy Bridge jest on 20-etapowy. Dzięki zwiększeniu liczby faz w potoku wykonawczym zmniejsza się ryzyko wystąpienia sytuacji, w której operacje muszą zostać wstrzymane ze względu na to, że któraś z jednostek wykonawczych będzie zajęta lub nie ma jeszcze wygenerowanych potrzebnych danych.

W procesorze Prescott (mikroarchitektura NetBurst) mieliśmy do czynienia z aż 31 etapowym potokiem wykonawczym
Należy jednak pamiętać, że zwiększanie liczby faz potoku wykonawczego ma też swoje ograniczenia, dlatego nie projektuje się procesorów np. stu, czy dwustufazowych, a wspomniany Prescott z 31 etapami uważany jest za procesor, w którym w zanczący sposób przekroczono już rozsądną liczbę faz. Najpoważniejszym ograniczeniem w zwiększaniu liczby faz w potoku wykonawczym jest struktura programów, a mówiąc ściślej ich rozgałęzienia, czyli rozkazy skoków oraz instrukcje warunkowe, które są wykonywane lub pomijane w zależności od rezultatów poprzednich operacji. Wykonanie takiej instrukcji, bądź jej niewykonanie może sprawić, że cała następująca po niej zawartość potoku wykonawczego przestaje być aktualna i trzeba opróżnić i ponownie napełnić potok od rozkazu, do którego zastał wykonany przeskok.
Biorąc pod uwagę fakt, że napełnienie 15-fazowego potoku wymaga 15 cykli zegara, a 20-fazowego 20 cykli zegara, staje się jasne, że konstruktorzy projektujący procesory muszą znaleźć rozsądny kompromis między długością potoku i związanym z tym przyspieszeniem działania układu, a mogącymi wystąpić sporymi opóźnieniami spowodowanymi koniecznością ponownego napełnienia. Dodatkowo całą sprawę komplikuje to, że od 10 do 20% kodu programu skompilowanego dla procesorów kompatybilnych z układami x86 to instrukcje skoku. Oznacza to, że co siódma instrukcja może wymagać opróżnienia potoku wykonawczego.




