Wbrew pozorom architektura Fermi nie odbiega znacząco od starszej serii kart tego producenta. Poczynione zmiany można by tu mniej więcej porównać do tego, z czym mieliśmy do czynienia podczas premiery nowego Radeona HD 5800. Za motorem przeprojektowania układu oraz wprowadzeniu wszelkich udoskonaleń stanął zatem wymóg zgodności z API DirectX11.
Jednak składający się z 3 miliardów tranzystorów układ nie stanowi do końca rozszerzonej wersji swojego poprzednika. Został zaprojektowany niemal zupełnie od początku - nie tylko by sprostać wymaganiom specyfikacji DX11, ale również by o wiele sprawniej poradzić sobie z warstwą programową dla obliczeń GPGPU.

Zdjęcie układu GF100 wykonane pod mikroskopem elektronowym
Serce wykonanego w technologii 40 nanometrów rdzenia stanowi 16 bloków procesorów SM (Stream Multiprocessors) podzielonych na 4 autonomiczne klastry GPC (Graphics Processing Clusters). Na każdy z tych bloków przypadają po 32 rdzenie CUDA. W porównaniu do GT200, samych bloków jest zatem znacznie mniej, jednak zawierają czterokrotnie większą liczbę pojedynczych procesorów. Łączna liczba gotowych do obliczeń równoległych rdzeni nowego układu wynosi więc 512. Warto zauważyć, że konkurencyjny Radeon oferuje ich 320, ale sposób działania oraz sama ich budowa znacząco się różni.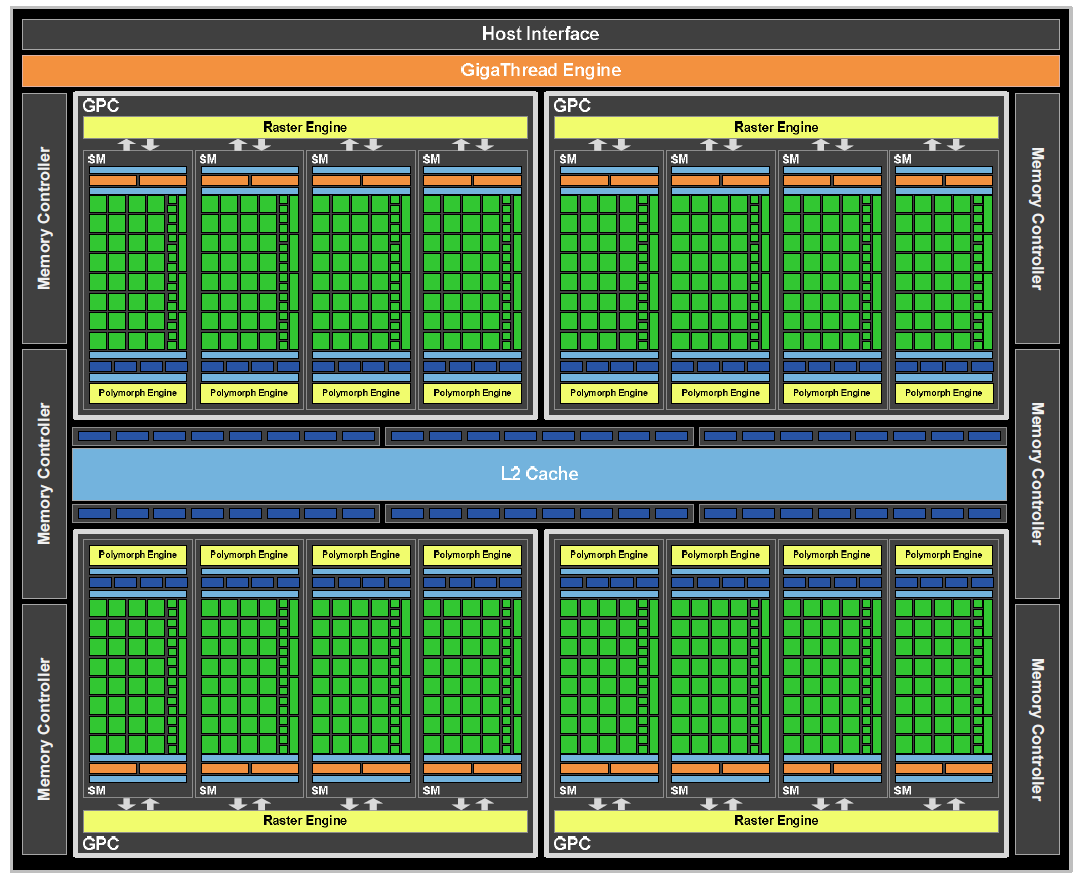
Architektura Fermi to, oprócz bardziej efektywnych klastrów GPC, także nowy silnik rozdzielania wątków GigaThread, kontroler hosta interpretujący komendy procesora centralnego, rezygnacja z autonomicznych jednostek TPC (Texture Processing Clusters), pojemna i szybka pamięć podręczna drugiego poziomu (L2 cache) oraz 6 przebudowanych bloków ROP, w których znajdziemy po 8 jednostek renderujących. Bloki ROP komunikują się z jednej strony poprzez pamięć cache L2 z poszczególnymi klastrami GPC, a od strony interfejsu pamięci z sześcioma 64-bitowymi partycjami kontrolera RAM.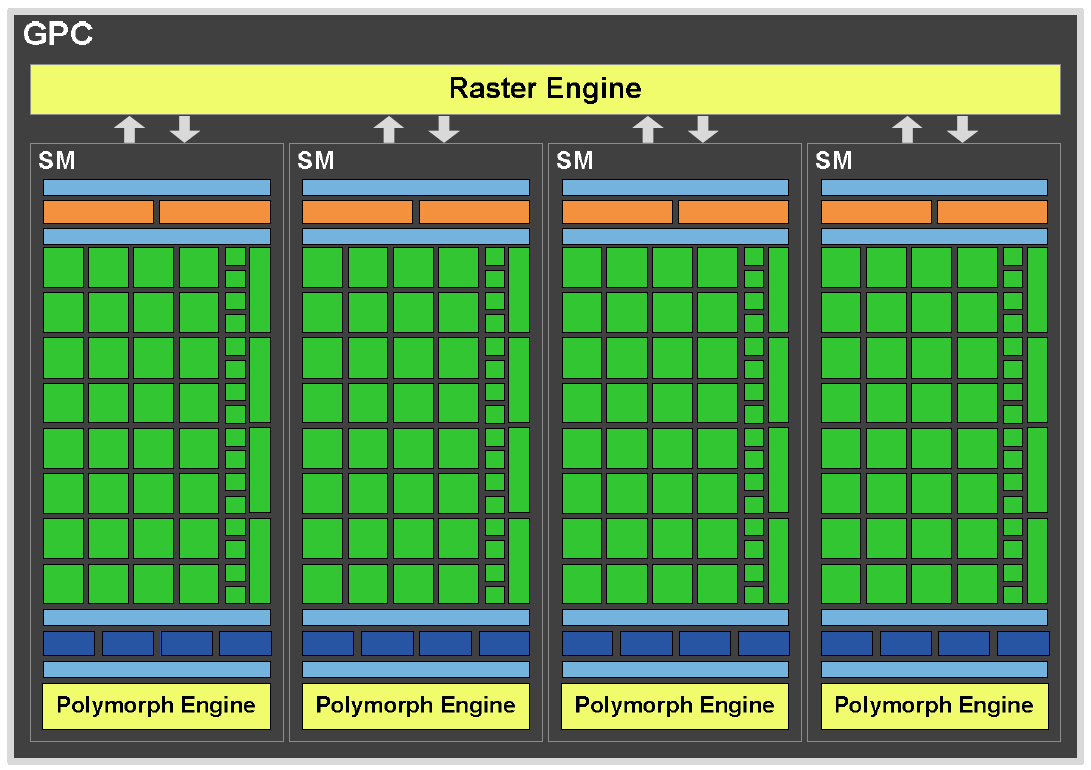
Pojedynczy klaster GPC został skonstruowany w taki sposób, aby mógł też pełnić funkcje niezależnego GPU. W GF100 mamy więc do czynienia ze współpracującymi ze sobą czterema procesorami, gdzie w skład każdego z nich wchodzi po 128 rdzeni CUDA. 
W usprawnionych rasteryzatorach poczyniono zmiany, które poskutkowały możliwością przepuszczenia przez potok do 8 pikseli na zegar, co dla całego układu daje prędkość 32 rasteryzacji piksela na zegar. Możliwość pracy równoległej tej jednostki usprawniła ponadto cały proces przekształceń geometrycznych, z których najbardziej obciążającą jest teselacja, czyli podział wielokątów.
Każdy z 16 bloków SM ma dedykowaną jednostkę polimorficzną (Polymorph Engine) odpowiedzialną za przekształcenia geometryczne. W stosunku do układów starszej generacji zastąpiono nią blok znany pod nazwą Stream Out, cechujący się - jak na wymogi zgodności z Shader Model 5.0 - zbyt małą elastycznością. Własne teselatory przypadające po jednym na blok SM oraz wydajna jednostka rasteryzacji spowodowały według NVIDII aż ośmiokrotne przyspieszenie obliczeń geometrii. Trzeba zatem przyznać, że jest to jedna z najbardziej istotnych zmian w stosunku do układu GT200, jakie zaserwował nam obecnie producent.
Jak już wspomniałem, w GF100 zrezygnowano z niezależnych klastrów jednostek teksturujących (TPC). Tym razem każdy SM ma po cztery jednostki zdolne do zaadresowania pojedynczej tekstury oraz pobrania czterech ich próbek na cykl zegarowy. Pomimo zastosowania mniejszej liczby jednostek aniżeli w GT200, udało się jednak podnieść ich efektywność. Jednostki przeniesiono do wewnątrz bloku SM, co z jednej strony wpłynęło na szybszą komunikację z procesorami strumieniowymi (dedykowana pamięć L1 dla tekstur), a z drugiej pozwoliło im pracować z dwukrotnie wyższą częstotliwością (taktowanie CUDA Cores). Dzięki temu „prostemu” zabiegowi 60 jednostek TMU w GF100 odpowiada mniej więcej 120 znanym z klasycznego układu o podobnym taktowaniu domeny ROP. TMU w nowym układzie obsługują także dwa nowe formaty kompresji BC6H oraz BC7, zgodne z wymogami API DirectX11, redukujące zużycie pamięci dla tekstur HDR.
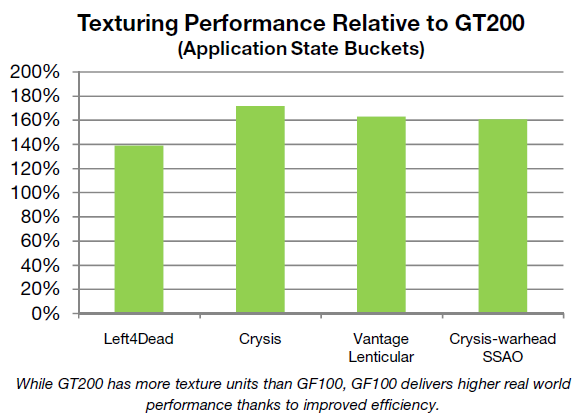
Wydajność teksturowania na tle układu GT200




