ATi rozłożyło ciężar obliczeń na różne elementy układu. Efektem tego jest architektura wielowątkowa (multi-threaded) lub mówiąc językiem ATI, Ultrawątkowa (Ultra-Threaded Architecture). Nazwa tej technologii brzmi podobnie do intelowskiej Hyper-Threading (współbieżność wielowątkowa) i cechuje ją także podobny cel, czyli jak najwydajniejsze wykorzystanie zasobów obliczeniowych procesora i zminimalizowanie czasu, w którym jego narzędzia wykonawcze spoczywają bezczynnie.
architektura R520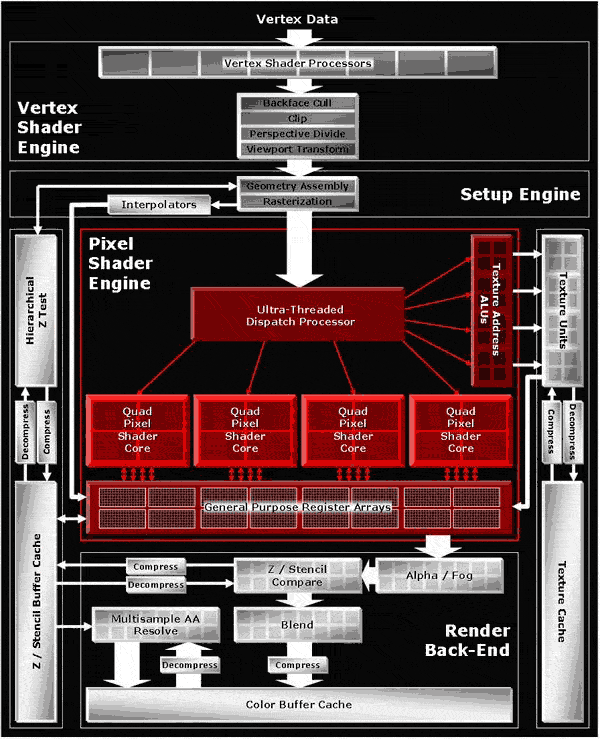
Istnieją pewne zbieżności nie tylko między architekturą Radeona X1000 (R500), Radlona 9000 (R300) i Radeona X800 (R400), ale także z nową architekturą zastosowaną w Xbox 360 GPU.
Na przykład, GPU Radeona X1000 wyposażony jest w zintegrowany inteligentny układ przełączający, tak zwany Ultra-Threading Dispatch Processor, którego zadaniem jest rozkładanie ciężaru obliczeniowego pomiędzy czwórki procesorów pikselowych (każda czwórka składa się z czterech procesorów pikselowych, z których każdy jest w stanie przetwarzać shader dla bloku 2x2 piksele w pojedynczym cyklu zegara) a układy zajmujące się odwzorowaniem tekstur.
Ultra-Threading Dispatch Processor dzieli materiał pikselowy, który ma przetworzyć na małe wątki o rozmiarze 4x4 piksele. Jest także w stanie wykryć momenty przestoju procesorów pikselowych w czwórkach i przypisać im nowe zadania. Jeśli dalsze wykonanie shadera wymaga danych, które nie są jeszcze gotowe, procesor arbitrażowy zatrzymuje dany wątek aż do momentu, w którym napłyną dane. Zwalania on tym samym ALU umożliwiając realizację innych wątków i maskując opóźnienie samplowania tekstur, na przykład tych przechowywanych w cache lub pamięci. Według ATI, architektura ta pomaga osiągnąć wydajność procesorów pikselowych dla każdego shadera na poziomie 90% .
Szybkie przełączanie pomiędzy wątkami wymaga przechowywania pośrednich danych dla każdego z nich. ATI korzysta ze specjalnego rejestru (General Purpose Register Array) bardzo wydajnie połączonego z procesorami pikseli, tak jak to miało miejsce w przypadku poprzednich GPU ATI.
Nowe rozwiązania ATI, zgodne ze standardem Shader Model 3.0, w pełni obsługują pętle, rozgałęzienia, skoki i podprogramy. Kontrola przepływu pomaga im wykonać teoretycznie nieskończoną liczbę mini-programów shaderów. Rodzina procesorów Radeon X1000 wykonuje wszystkie operacje w 128 bitowym formacie zmiennoprzecinkowym, który minimalizuje możliwość pojawienia się skumulowanych i pogarszających jakość obrazu błędów związanych z zaokrąglaniem wyników obliczeń.
Powiększyła się liczba równocześnie wykonywanych wątków kodowych, ale rozmiar każdego z wątków został zmniejszony do rozmiaru 4x4 piksele. Pomaga to osiągnąć wyższą wydajność przy dynamicznym rozgałęzianiu / skokach.

Korzyści wynikające z podejścia ATI są oczywiste: wydajność dynamicznego rozgałęziania/skoków pogarsza się w znaczącym stopniu wraz ze wzrostem wielkości wątku i staje się nieopłacalna w przypadku wątków o rozmiarze 64x64 piksele. Wyższy model, Radeon X1800 (R520), jest w stanie wykonać do 512 wątków kodu shader równocześnie, podczas gdy niższe modele ograniczone są 128 równoczesnymi wątkami.
Kolejną interesującą cechą Radeona X1800 jest specjalny, dedykowany układ zajmujący się przewidywaniem skoków, wykonywaniem określonych gałęzi. Dzięki wykonywaniu jednej instrukcji sterowania przepływem danych (warunki, pętle, podprogramy) na cykl zegara, układ ten jest w stanie zredukować obciążenie głównego ALU. Shadery, które używają instrukcji sterowania przepływem danych wykonywane są w mniejszej niż zwykle liczbie cyklów. Może to nieść ze sobą znaczny przyrost wydajności w przypadku wersji pixel shader 3.0 w porównaniu z rozwiązaniami nVidii.
Z racji tego, że współczesne gry komputerowe powszechnie wykorzystują pixel shader, ATI kładzie duży nacisk na wydajność GPU ze szczególnym jego uwzględnieniem. Pixel pipeline w GeForce 7 zostało także poprawione w porównaniu do poprzednich GPU nVidii.
Cel osiągnięto dzięki zwiększonej liczbie ALU. Każdy procesor pikselowy R520 wyposażony jest w 2 skalarne i 2 wektorowe ALU zdolne do wykonywania do 4 instrukcji w cyklu zegarowym (2 typy instrukcji ADD + modyfikator, 2 typy instrukcji ADD/MUL/MADD).
Nowy Radeon to także pierwszy GPU, w którym układy odpowiedzialne za texture-mapping (mapowanie tekstur) i texture addressing (adresowanie tekstur) komunikują się z procesorem shader, nie bezpośrednio, ale poprzez Ultra-Threading Dispatch Processor. Jest to jeszcze jednym środkiem optymizacji całego rdzenia graficznego, którego głównym celem jest ukrycie opóźnień w adresowaniu tekstur. Po prostu łatwiej jest koordynować wszystkie układy za pomocą jednego centrum kontrolnego.
ATI Technologies twierdzi, że całkowita wydajność R520 równa jest 83Gflopom, podczas gdy nVidia informuje, że G70 osiąga 165Gflopów. Wynik ten jest dwukrotnie większy od wydajności układu ATI, ale porównanie jest prawdopodobnie błędne. Prędkość GeForce 7800 GTX została zmierzona przy użyciu instrukcji MADD, a nie wiemy w jaki sposób wydajność swoich kart mierzyła ATI.
Procesory vertex Radeona X1000 zostały zaprojektowane w podobny sposób do architektury GeForce 7 nVidii. Każdy procesor składa się z dwóch układów, wektorowego i skalarnego, z taką różnicą, że procesor vertex G70 ma 32 bitowe ALU, podczas gdy w X1000 jest 128 bitowy. Cecha ta pozwala na emulowanie centralnego procesora na GPU.
Nowe procesory vertex potrafią wykonywać dwie instrukcje w jednym cyklu zegara. Zwykły shader może mieć długość 1024 instrukcji lub być teoretycznie nieskończony przy wykorzystaniu instrukcji kontroli przepływu. Oczywiście procesory vertex X1000 są w pełni zgodne ze specyfikacją Shader Model 3.0.
Teoretycznie, wydajność vertex shader X1800 XT powinna być dużo większa niż tego, w który wyposażona jest karta GeForce 7800 GTX, ponieważ jego procesor pracuje z dużo wyższą częstotliwością.




