






Słyszeliście pewnie o AlphaGo – to oparty na sztucznej inteligencji program zespołu DeepMind, który opanował sztukę gry w go do tego stopnia, że bez większych problemów wygrał pojedynki z arcymistrzami uznawanymi za najlepszych z najlepszych. Jeśli byliście pod wrażeniem, to musicie wiedzieć, że znalazł się wreszcie jego pogromca – nazywa się… AlphaGo Zero.
AlphaGo Zero również jest programem bazującym na sztucznej inteligencji, ale nieco innego rodzaju. O ile bowiem ten pierwszy uczył się najlepszych ruchów i strategii poprzez toczenie pojedynków z ludzkimi przeciwnikami, tak AlphaGo Zero uczył się sam (tzw. reinforcement learning). Rozgrywał sam ze sobą partię za partią (początkowo nie znał żadnych ruchów – wyłącznie podstawowe zasady gry – ale z czasem uczył się tego, jakie najszybciej i najskuteczniej doprowadzą go do zwycięstwa).

Tak samouczący się program już po 3 godzinach zaczął grać jak ludzki amator (robiąc jeszcze bardzo proste błędy), a po 19 godzinach miał już wiedzę na temat bardziej zaawansowanych strategii. Po trzech dniach treningu był w stanie pokonać wersję AlphaGo z 2015 roku (tę, która pokonała arcymistrza Lee Sedola) i to wynikiem 100:1. Po trzech tygodniach zrównał się poziomem z wersją, która pokonała wszystkich najlepszych zawodników („Master”). I wreszcie po 40 dniach zdołał wygrać ze wspomnianym „Masterem”.
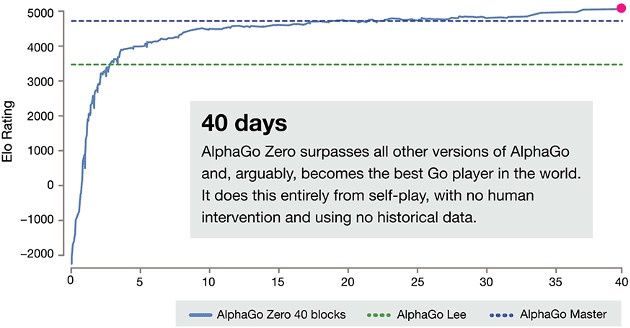
Krótko mówiąc: nie trzeba było czekać półtora miesiąca, by program-samouk stał się najlepszym zawodnikiem w go na świecie – lepszym od rozwijanego od lat AlphaGo i ludzkich zawodników z wieloletnim doświadczeniem. Taka sztuczna inteligencja, która nie musi ograniczać się do ludzkiej wiedzy, może pomóc w rozwiązaniu problemów, z którymi do tej pory ludzkość sobie nie poradziła. Taki jest potencjał.
Źródło: DeepMind Blog









![AMD Ryzen 7 7700X3D miał być hitem. Ja go nie kupię (przynajmniej na razie) [Opinia]](https://v.wpimg.pl/NDE2YjdiYSUkUC9ZSxJsMGcIewMNS2JmMBBjSEtae3Q9HT8DCAw8ITVddw0WHD4lMkJ3GghGLzQsHS9bSw0nNzVeOBNLDCMmIFZ2XlALLXV2AWBHB1x9cGgGOAkGRHZwIFF0XVZfLXB0BDtdBlt6Zjg)


