







NVIDIA ogłosiła udostępnienie modeli Audio2Face jako open source wraz z kompletnym zestawem narzędzi programistycznych (SDK). Jednocześnie firma otworzyła platformę treningową Audio2Face, umożliwiającą dostrajanie modeli do specyficznych zastosowań.
Audio2Face to zestaw modeli sztucznej inteligencji generatywnej, które umożliwiają tworzenie animacji twarzy zsynchronizowanych z mową. Algorytmy analizują akustyczne cechy nagrania audio, takie jak fonemy i intonacja, a następnie generują strumień danych animacji odwzorowujących mimikę i ruch warg.
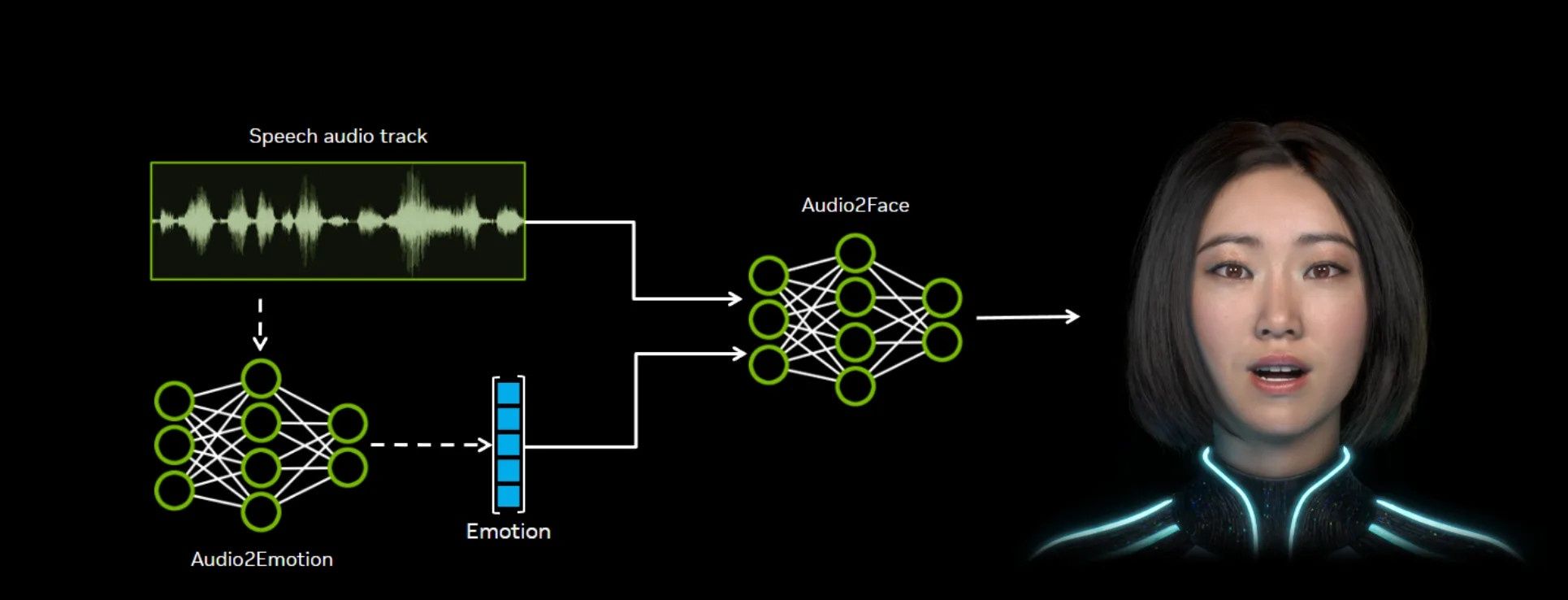
Dane animacyjne mogą być renderowane offline w ramach przygotowanych wcześniej sekwencji lub używane w czasie rzeczywistym do animowania postaci sterowanych przez AI. Warto zobaczyć prezentację poniżej.
WIDEO
Rozwiązanie znajduje zastosowanie w grach wideo, produkcjach medialnych i systemach obsługi klienta. Z technologii korzystają już m.in. Codemasters, GSC Games World, NetEase, Perfect World Games oraz firmy tworzące narzędzia, takie jak Convai, Inworld AI, Reallusion, Streamlabs i UneeQ.
Otwartoźródłowe komponenty
Udostępnienie Audio2Face w formie open source oznacza, że społeczność deweloperów zyskuje dostęp do kodu, który można rozwijać i modyfikować. Dzięki temu narzędzia mogą być adaptowane do różnych środowisk produkcyjnych i poszerzane o dodatkowe funkcje.
W ramach projektu dostępne są:
- Audio2Face SDK – biblioteki i dokumentacja do uruchamiania animacji lokalnie i w chmurze.
- Wtyczka do Autodesk Maya (v2.0) – umożliwia przesyłanie audio i odbieranie animacji twarzy bezpośrednio w Maya.
- Wtyczka do Unreal Engine 5 (v2.5) – obsługuje wersje UE 5.5 i 5.6, pozwala integrować animacje w czasie rzeczywistym.
- Framework treningowy Audio2Face (v1.0) – narzędzie do tworzenia modeli na podstawie własnych zbiorów danych.
- Przykładowe dane treningowe – zestaw startowy do testowania i nauki modeli.
- Modele Audio2Face – regresyjne (v2.2) oraz dyfuzyjne (v3.0) do generowania ruchu warg.
- Modele Audio2Emotion – produkcyjne (v2.2) i eksperymentalne (v3.0) do wnioskowania o emocjach na podstawie sygnału audio.
NVIDIA kieruje narzędzia do twórców gier, aplikacji 3D oraz systemów interakcji głosowej. Dokumentacja i kod źródłowy są dostępne w repozytoriach otwartego oprogramowania oraz w ramach platformy NVIDIA ACE for Games.

Redaktor prowadzący serwis Benchmark.pl, dziennikarz technologiczny z ponad 15-letnim doświadczeniem. Specjalizuje się w tematach związanych ze sprzętem komputerowym, rozwojem technologii AI oraz trendami w branży IT. W swojej pracy stawia na rzetelność, praktyczne podejście i pasję do nowinek technologicznych, koncentrując się na ocenie produktów pod kątem ich wartości i opłacalności dla użytkowników. W wolnym czasie angażuje się w wolontariat, aktywnie spędza czas oraz rozwija swoje zainteresowania i pasje.












