
Nvidia wprowadza najpotężniejszy akcelerator obliczeniowy – to prawdziwy mocarz

Czekaliśmy, czekaliśmy i się doczekaliśmy! Nvidia oficjalnie zaprezentowała architekturę Hopper, która znajdzie zastosowanie w akceleratorach obliczeniowych – producent mówi o ogromnym wzroście wydajności, która pozwoli zrewolucjonizować ten rynek.
Podczas konferencji GTC 2022 poznaliśmy pierwsze szczegóły na temat układów graficznych z generacji Nvidia Hopper (nazwanych na cześć Grace Hopper, pionierki amerykańskiej informatyki). Nowa architektura ma zadanie przyspieszyć operacje programowania dynamicznego — technikę rozwiązywania problemów wykorzystywaną w algorytmach genomiki, obliczeniach kwantowych i optymalizacji tras.
Nowe układy graficzne znajdą zastosowanie w systemach obliczeniowych i superkomputerach. Warto jednak bliżej przyjrzeć się temu co zaprezentowała Nvidia.

Architektura Nvidia Hopper. Jest moc!
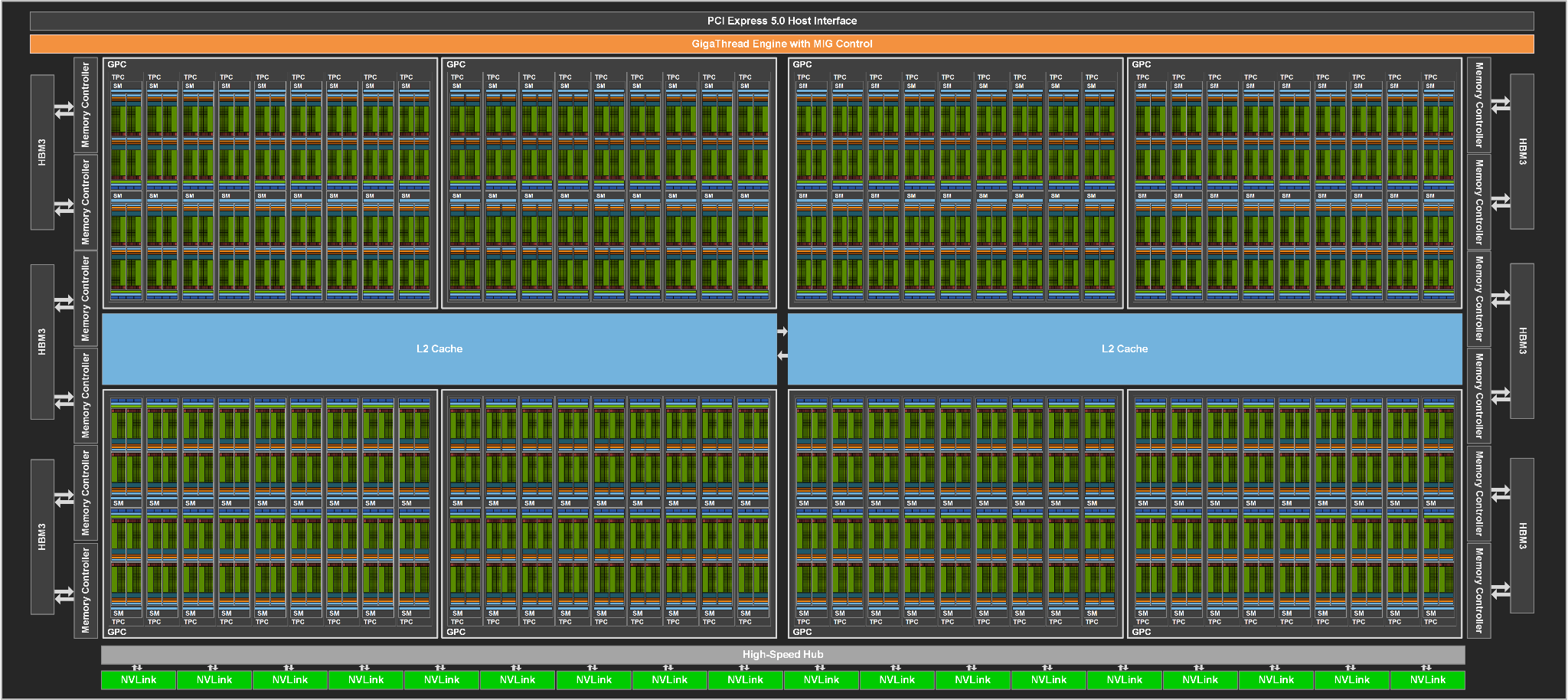
Nowa architektura została zaprojektowana typowo z myślą o systemach obliczeniowych. Póki co producent przygotował jeden układ graficzny – to rdzeń GH100, który został wykonany w 4-nanometrowej litografii TSMC (TSMC N4) i składa się z 80 miliardów tranzystorów (układ ma powierzchnię 814 mm2, czyli zbliżoną do rdzenia GA100 – podobnego układu z generacji Nvidia Ampere).
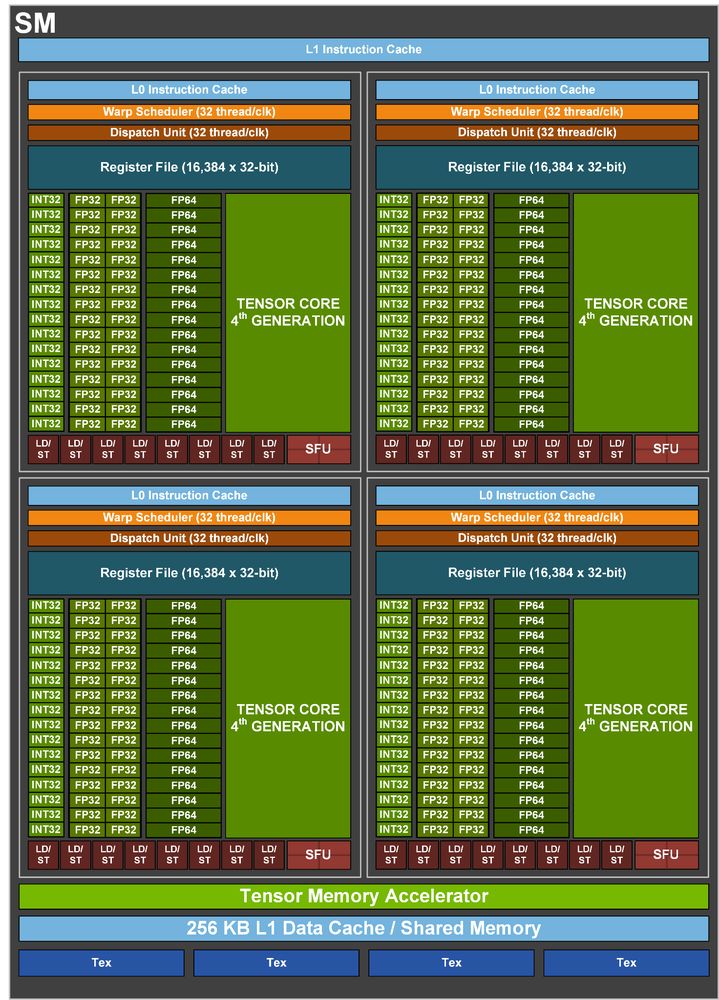
Nvidia Hopper - budowa bloku SM
Procesor graficzny GH100 oferuje też potężną specyfikację. Cały układ graficzny obejmuje 18 432 rdzeni CUDA i 576 rdzeni Tensor (4. generacji), a ponadto przewidziano 96 GB pamięci HBM3/HBM2e 6144-bit.
Akcelerator obliczeniowy Nvidia H100 – znamy wydajność
Nowy układ graficzny posłużył do budowy profesjonalnego akceleratora obliczeniowego Nvidia H100 – jest on dostępny w postaci modułu SXM5 oraz karty rozszerzeń pod PCI-Express 5.0. Warto jednak zaznaczyć, że druga wersja oferuje gorszą specyfikację (ale też cechuje się dużo mniejszym zapotrzebowaniem na energię elektryczną).
| Model | Nvidia A100 (SXM) | Nvidia H100 (SXM) | Nvidia H100 (PCIe) |
| Generacja | Nvidia Ampere | Nvidia Hopper | Nvidia Hopper |
| Litografia | TSMC N7 | TSMC N4 | TSMC N4 |
| Układ graficzny | Ampere GA100 | Hopper GH100 | Hopper GH100 |
| Rdzenie CUDA | 6912 | 15872 | 14592 |
| Rdzenie Tensor | 432 | 528 | 456 |
| Wydajność FP64 | 9,7 TFLOPS | 30 TFLOPS | 24 TFLOPS |
| Wydajność FP64 Tensor | 19,5 TFLOPS | 60 TFLOPS | 48 TFLOPS |
| Wydajność FP32 | 19,5 TFLOPS | 60 TFLOPS | 48 TFLOPS |
| Wydajność FP32 Tensor | 312 TFLOPS | 1000 TFLOPS | 800 TFLOPS |
| Wydajność INT32 | 19,5 TOPS | 30 TOPS | 24 TOPS |
| Wydajność INT8 Tensor | 1248 TOPS | 4000 TOPS | 3200 TOPS |
| Pamięć VRAM | 80GB HBM2e 5120-bit | 80 GB HBM3 5120-bit | 80 GB HBM2e 5120-bit |
| Przepustowość pamięci | 1,55 TB/s | 3 TB/s | 2 TB/s |
| TDP | 400 W | 700 W | 350 W |


Wydajność karty robi ogromne wrażenie – to największa i najpotężniejsza konstrukcja, jaka została przygotowana przez „zielonych”.

Producent chwali się, że akcelerator Nvidia H100 (SXM) oferuje 3-krotnie wyższą wydajność obliczeniową FP64, TF32, FP16 oraz 6-krotnie wyższą FP8 względem akceleratora Nvidia A100 (poprzednika z generacji Ampere). Przepustowość pamięci wzrosła 1,5-krotnie.
Warto dodać, że akcelerator Nvidia H100 jest obsługiwany przez wszystkie najważniejsze narzędzia programistyczne, dzięki czemu można go używać do przyspieszania aplikacji od AI po HPC (z tej też okazji producent wydał ponad 60 aktualizacji swoich bibliotek programistycznych, które przyspieszą prace w zakresie obliczeń kwantowych, genomiki, odkrywania nowych leków, cyberbezpieczeństwa czy badań nad 6G)
Dostępność kart Nvidia H100
Akceleratory Nvidia H100 mogą być wdrożone w centrach danych i systemach chmurowych. Oczekuje się, że takie konstrukcje będą dostępne jeszcze w tym roku u wiodących dostawców usług w chmurze i producentów sprzętu.


Nvidia daje możliwość połączenia nawet 32 systemów DGX H100
Przy okazji zaprezentowano też nowy system obliczeniowy DGX H100, który został wyposażony w osiem akceleratorów obliczeniowych Nvidia H100 - zostały one połączone za pomocą łącza NVLink czwartej generacji (dzięki zewnętrznemu przełącznikowi NVLInk można też połączyć do 32 węzłów DGX H100 w superkomputer Nvidia DGX Super POD).
Jeśli jesteście zainteresowani szczegółami, poniżej możecie zobaczyć powtórkę konferencji GTC 2022, na której zaprezentowano nowe akceleratory Nvidia Hopper.


Źródło: Nvidia, ComputerBase, WCCFTech








Komentarze
14Szanowny Autor planuje zakup takiej karty?
Właściwie czy układowi GH100 brakuje jakiś jednostek, aby na jego podstawie zbudować kartę z wyjściami na monitory?
treść artykułu: "Nowe układy graficzne znajdą zastosowanie w systemach obliczeniowych"
tytuł artykułu: "najpotężniejszy akcelerator obliczeniowy"
przy okazji "algorytmach genomiki" co to **** the **** jest ?????? o algorytmach genetycznych na serio nie słyszałeś?
chłopie weź się zastanów co piszesz. to nie jest żadna karta graficzna ani inny akcelerator graficzny, lecz akcelerator obliczeniowy. co najwyżej jest oparty na technologii układów grafiki. ja twoje artykuły jak czytam, to albo ostrzec innych przed informacyjną sieczką, albo żeby się dowiedzieć że technologia X została przez firmę Y wprowadzona na rynek. Twoich opisów raczej nie czytam z powodu kompletnego pomieszania faktów.
Bardzo bym chciał abyś ciągnął jakość tego portalu w górę. na serio.
Tak, że jeśli odpowiedzią AMD będą udane układy w architekturze MCM, to przypuszczalnie będziemy mieli Potop jak w procesorach.
W tabelce powyżej H100 SXM ma 15872 rdzeni Cuda FP32, czyli 124 jednostek SM, ponieważ na diagramie pojedynczego SM jest 128 FP32.
Na tym samym diagramie widać, że pojedynczy SM to 4 rdzenie Tensor, czyli całość powinna mieć 496 rdzeni Tensor, a w tabelce jest 528.
Wiem, że takie same liczby są na videocardz, ale to wydaje mi się niespójne.
Jak dla mnie, najprawdopodobniej jest to 132 SM i 16896 rdzeni Cuda FP32, co pasuje do 528 rdzeni Tensor.
Korzyść jest widoczna gołym okiem. N4 jest gęstsze od N5 o 8% więc jak N5 ma 171.2MTr/mm2 to N4 ma maksymalne upakowanie na poziomie niecałych 185MTr/mm2. Teraz gdy wiadomo ile mamy tutaj upakowanych tranzystorów na tak dużym układzie jak Archi Hooper od Nvidia widzimy, że osiągamy ponad 53% maksymalnego upakowania tranzystorów na mm2. Wiedząc o tym, że N3 ma osiągać maksymalnie ponad 291MTr/mm2 i przeliczając na 53% maksymalnego upakowania tranzystorów dla rynku HPC dostajemy ponad 154MTr/mm2 dla N3. Przejście z N7 na N4 przyniosło przyrost tranzystorów na mm2 o 32.82 miliona tranzystorów na mm2. Przejście z N4 na N3 przyniesie przypuszczalnie przyrost tranzystorów na mm2 aż o ponad 55 milionów. Z całą pewnością na mm2 znów skoczy do góry zużycie energii ale można liczyć na kolejny ogromny wzrosty Wydajności na Watt całego układu właśnie przez tą gęstość upakowania tranzystorów. A ludzie dalej myślą, że na jeszcze lepszy Ray Tracing (taki bardziej naturalny trzeba będzie czekać przynajmniej do 2030 roku (nie biorę pod uwagę tych co nawet o 2035 roku piszą bo to jest całkowity brak wyobraźni w tym co się właśnie dzieje).